果然人还是要工作的啊
Git
什么是Git
Git是目前世界上最先进的分布式版本控制系统。
分布式:
既然有分布式,自然就会有集中式。SVN就是集中式版本控制系统,其特点是版本库集中放置在中央服务器里,需要修改工程时,需要先从服务器里下载版本信息。工作完成后,需要再把版本信息推送回中央服务器。
这样,工作时必须要联网。
而Git不同,Git在每台主机里都有自己完整的版本信息库,多人协作时,只需要把自己在本地所作的修改推送给对方,就可以互相知道对方所作的更改了。
版本控制系统:
每一次更改工程时都使用Git做一次记录,Git就会记住你更改了什么内容。
需要退回到某个版本时,也可以方便地使用Git来回退。
下载git
Linux可以使用gpt-get install git下载
设置用户信息和邮箱
当我们对工程进行一些改动的时候,我们需要使用用户名和邮箱来作为标识,让其它人看到之后知道这些代码是被谁所改动的。
设置用户名和邮箱
1 | $ git config --global user.name "Your Name" |
查看当前Git登录的用户名和邮箱
$ git config --global user.name $ git config --global user.email
开始使用Git
初始化
从终端进入到想要记录的文件里,输入
1 | $ git init |
这时候如果该文件是空的,终端执行指令时会输入一句提示语,不影响程序执行。
执行完该指令,可以看到文件夹内部多了一个.git的隐藏文件夹
.git文件夹是git init后在当前目录生成的一个管理git仓库的文件夹,这里包含所有git操作所需要的东西
添加文件
我们在原文件夹下,添加一个文件a.txt,在里面随便写一些东西。
在刚刚的终端输入
1 | $ git add a.txt |
如果命令成功执行,不会有任何提示信息。
这时我们只是把文件添加到了仓库缓存区,想要正式提交到仓库,我们需要使用commit命令:
1 | $ git commit -m "添加了a" |
-m后面的信息是我们对于该版本的描述信息,该指令成功执行后,会输出一些提示信息,大体内容就是我们的描述信息,我们的版本做了哪些改动等等
1 | [master (root-commit) 494001b] 添加了a |
之所以每次更新仓库需要add和commit两步,就是因为我们add可以添加多个文件,可以每次写完一个文件就add一次,也可以一次add多个文件。到最后,工作告一段落了,我们就可以统一一次commit把前面add的文件都提交
修改文件
当我们需要修改某个文件时,先修改,修改之后,同样把修改过的文件使用add指令加进来,之后还是commit就可以了
比如我在上面的基础上,添加了b.txt和c.txt两个文件,并把a.txt里面的内容做了一些修改,我们就打开终端,输入:
1 | $ git add a.txt b.txt c.txt |
查看版本状态
假设我们的工程出现了一些问题,某个原本正常的功能经过我们的修改之后不正常了。我们现在想要把它回溯到正常的那个版本,但由于已经做了巨量的版本更改,忘记了具体是哪个了,这时,我们打开终端,输入
1 | $ git log |
这会显示出我们所有的版本记录
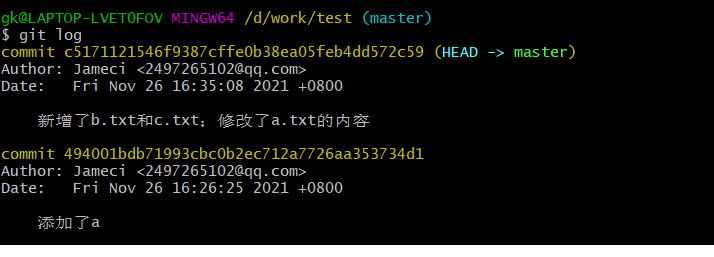
图中可以看到Git显示版本的格式,首先会把我们当前的版本列在最上面,然后按照时间顺序,由近到远。
每个版本的描述信息中,首先是一串十六进制数的版本id,这串id是我们找回版本的唯一凭据。之后是作者信息和更新时间,最后是我们自己写的版本描述信息。
Git使用HEAD表示当前的版本,上一个版本记为HEAD^,再上一个记为HEAD^^,上一百个可以用简洁的方法表示为HEAD^100
回到历史版本
查看并不能解决我们的问题,我们需要把工程回到历史上那个能用的版本
我们可以通过版本号来回溯,输入
1 | $ git reset --hard <版本id> |
如果知道回溯的版本是向上回溯几个版本的话,比如回溯到上一个版本,可以把版本号换为对应的HEAD^
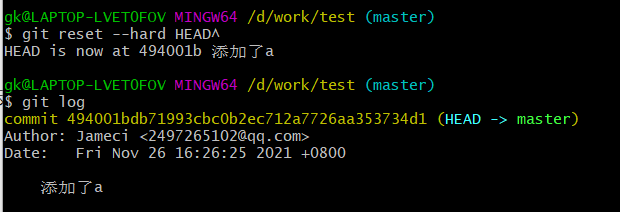
回溯成功后,文件夹中的内容也回到了当时的状态
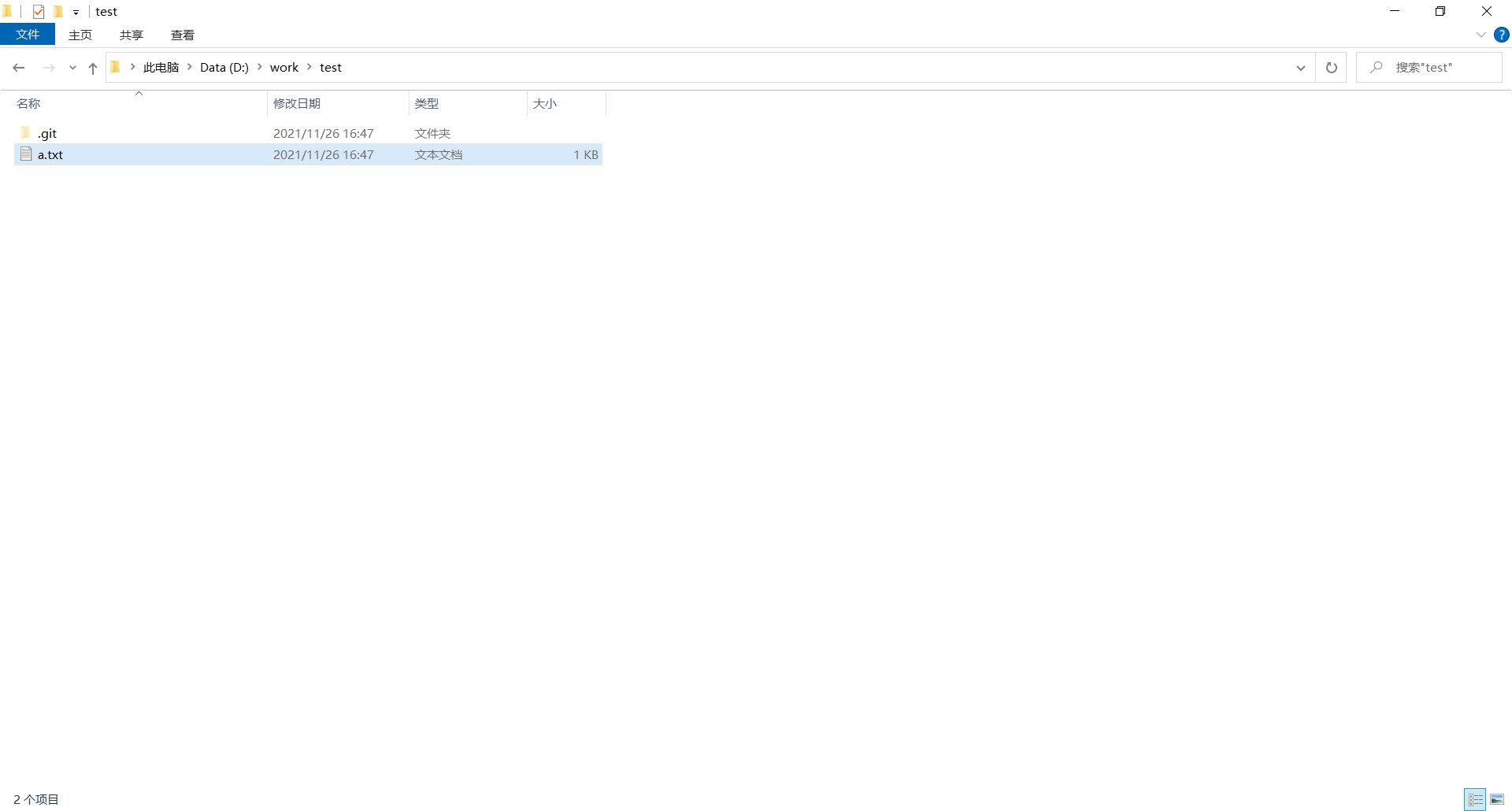
回到“未来”版本
书接上文,我们回溯到了历史版本,但我们又一次后悔了,想再回到当时出错的版本修改修改。如果你没有关闭命令行,里面保存这刚刚那一版本的id,我们仍然可以使用上面的reset命令回去。
但如果我们的命令行里已经没有刚刚的命令记录了,这时查看git log已经没有当时版本的id号了,是不是就回不去了呢?
不是的,我们依然可以使用
1 | $ git reflog |
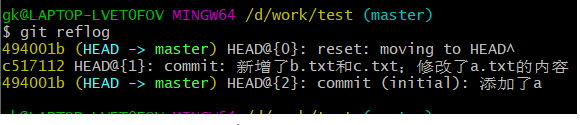
这里保存了我们之前操作的记录。使用前面的HEAD@{1}和c517112都可以回到当时的版本。
查看状态:理解工作区和暂存区
使用命令:
1 | $ git status |
查看当前的状态
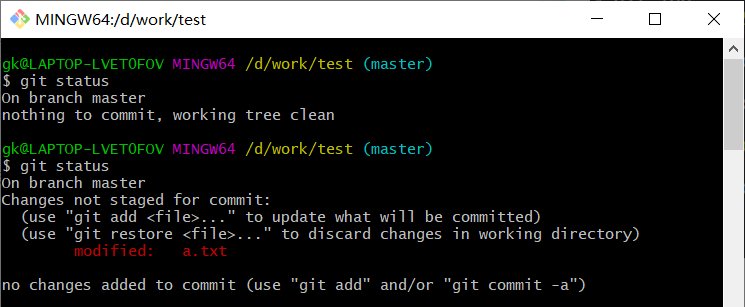
图中第一次输入命令时,文件夹中未作任何改动
第二次输入命令之前,我打开了之前的a这个文本文档,添加了一句话,再次查看状态可以看到红色的modified字样
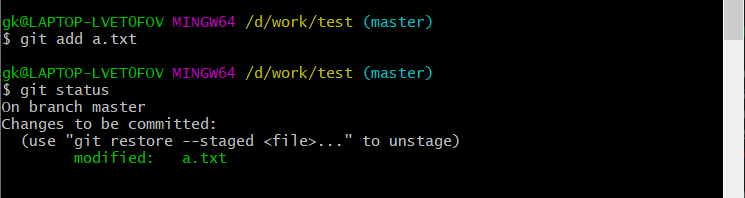
我们使用add命令将改动后的a添加进来,看到了绿色的modified字样
最后,我们使用commit提交修改,查看时又回到了未作改动的模样
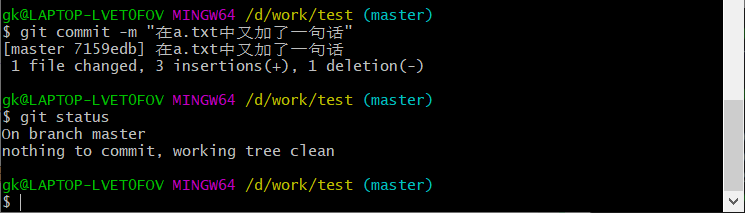
这里我们提一下工作区和版本库的概念。
工作区:就是你在电脑上看到的目录,比如目录下testgit里的文件(.git隐藏目录版本库除外)。或者以后需要再新建的目录文件等等都属于工作区范畴。
版本库:工作区有一个隐藏目录.git,这个不属于工作区,这是版本库。其中版本库里面存了很多东西,其中最重要的就是stage(暂存区),还有Git为我们自动创建了第一个分支master,以及指向master的一个指针HEAD。
使用git add把文件添加进去,实际上就是把文件添加到暂存区。
使用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支上。
工作区和暂存区的区别体现在下一节——撤销上
撤销修改
使用命令:
1 | $ git checkout -- 文件名 |
可以撤销所有未保存到暂存区的修改
我把a.txt的内容改一下,改为:
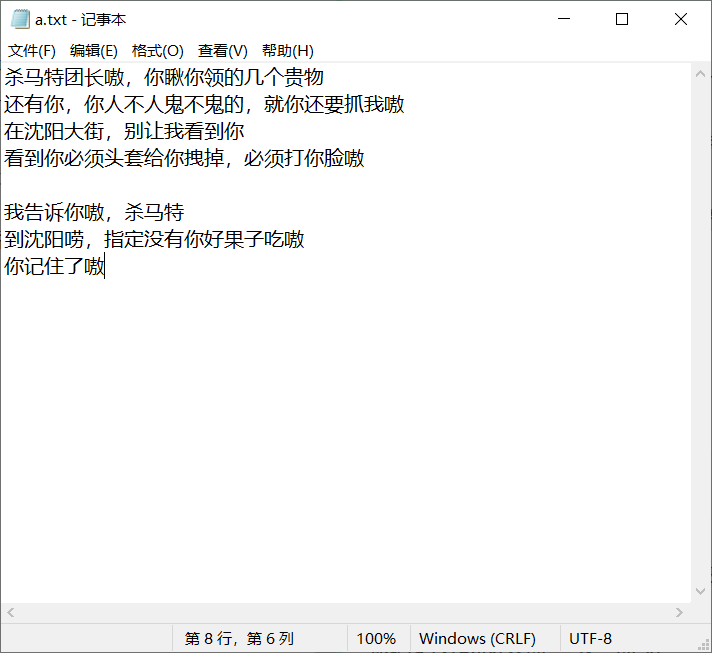
然后将其add到暂存区

并在这之后,再往后面添加一段,点击记事本文件里的保存
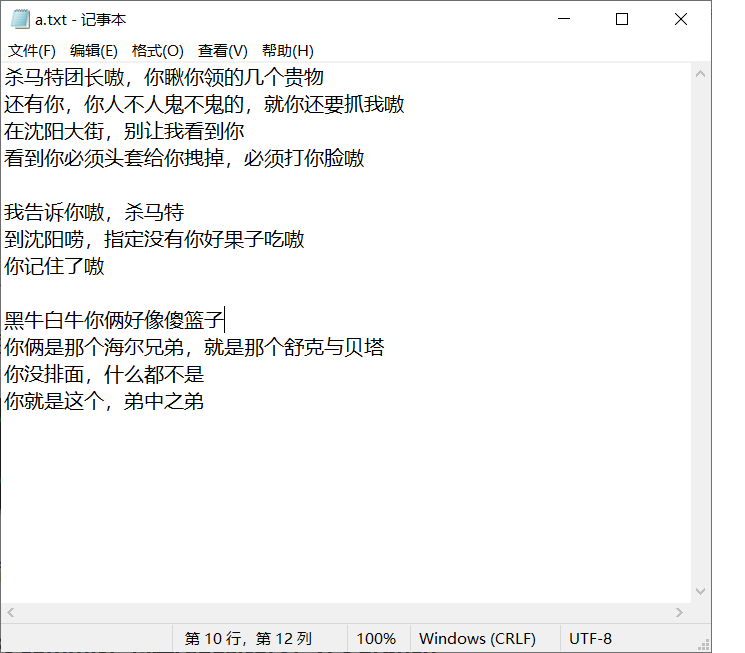
然后使用命令后打开原来的文件:
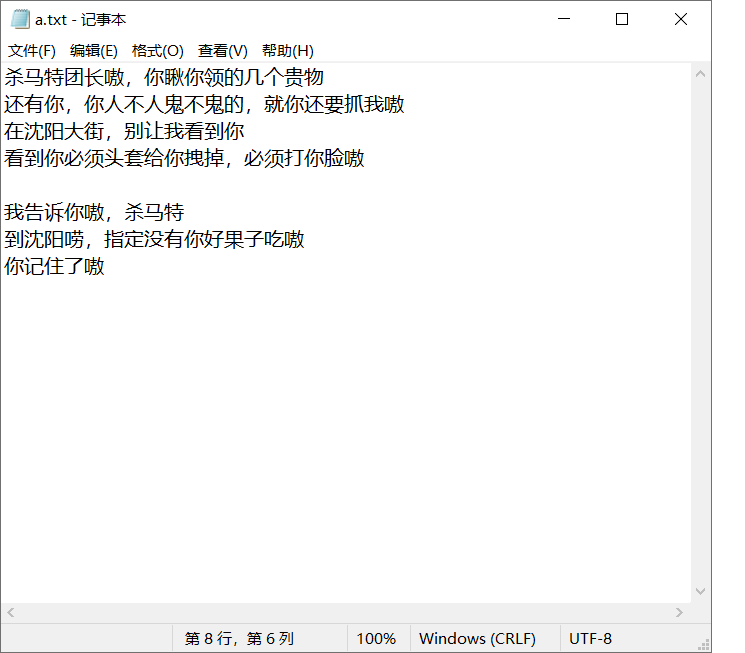
可以看到文件回到了上次添加后的状态
删除文件
如果要删除文件,先在目录删掉之后,再使用rm指令,类似于add指令一样,将删掉的文件添加进来之后commit就可以了
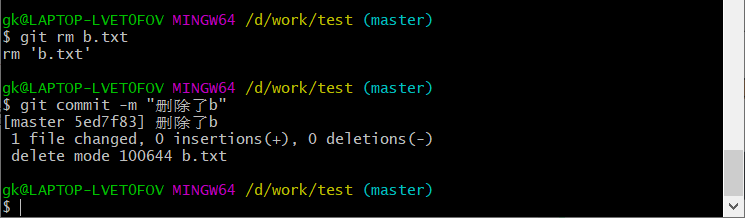
若要恢复未被添加进暂存区的已删除文件,我们也需要使用reset命令,格式和上面一样。
分支
在前面的演示中,所有的提交都是只有一条时间线的,也称为一个分支。上面的演示都是在master(也称为主分支)中进行的。
前面说到HEAD指向最近提交的版本,但严格来说,HEAD指向的是当前分支
创建并切换到dev分支
使用:
1 | $ git checkout -b dev |
建立名为dev的分支,并切换到dev分支
使用
1 | $ git branch |
查看所有分支

当前分支会高亮显示并添加一个分号
我们在a.txt里面添加内容:
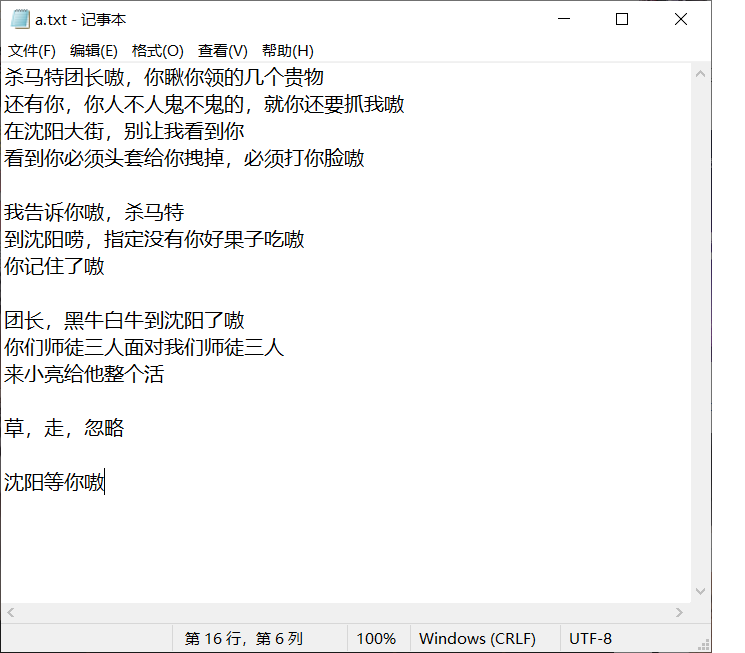
并commit,
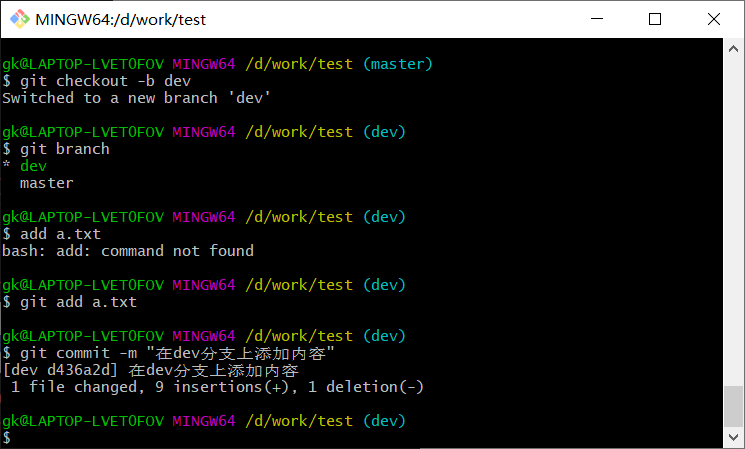
此时如果你切回主分支,你是看不到刚刚的添加的
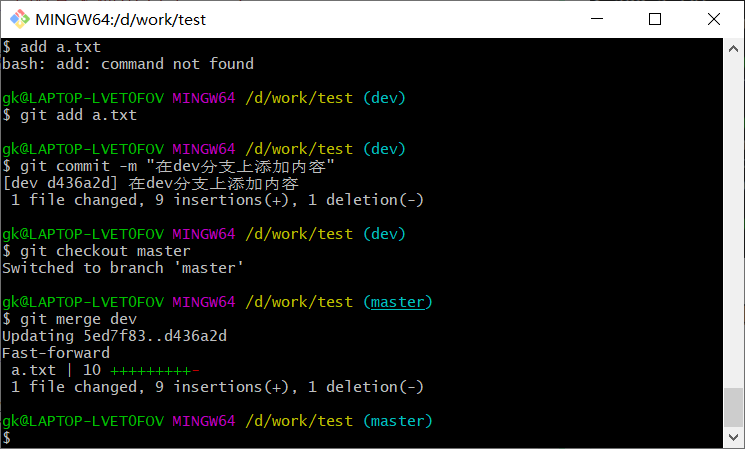
使用
1 | $ git checkout master |
切换回主分支
合并分支
我们可以把dev分支上的内容合并到分支master上了,可以在master分支上,使用如下命令
1 | $ git merge dev |
合并之后,主分支就能看见后面加的那几句话了
删除分支
合并之后,我们可以使用
1 | $ git branch -d dev |
删除dev分支
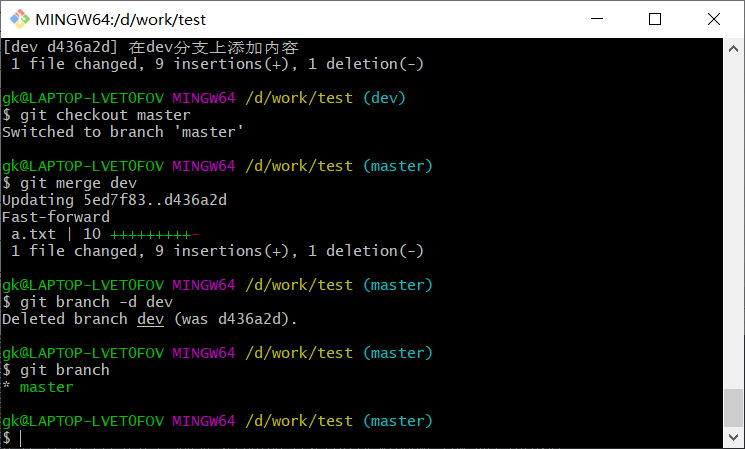
处理冲突
我们还是创建一个dev分支,并在a.txt下添加和master分支冲突的内容
切换回主分支,给a添加不一样的内容,造成冲突
然后合并:
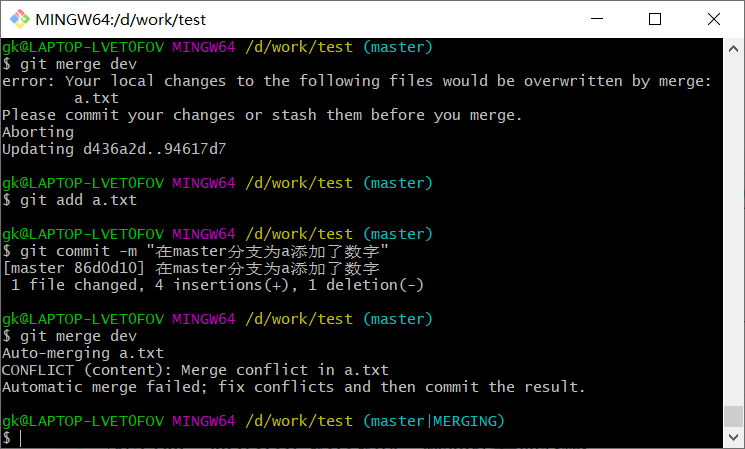
无法合并,提示冲突
此时查看文件,可以看到冲突的位置:

Git用<<<<<<<,=======,>>>>>>>标记出不同分支的内容,其中<<<HEAD是指主分支修改的内容,>>>>>dev 是指dev上
分支管理策略
通常合并分支时,git一般使用”Fast forward”模式,在这种模式下,删除分支后,会丢掉分支信息
使用带参数-–no-ff来禁用”Fast forward”模式。
1 | git merge --no-ff -m "使用-no-ff" dev |
Github
注册账号
略
创建SSH Key
在用户主目录下(Windows电脑的C:\Users\用户名文件夹),看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果有的话,直接跳过这一步,
如果没有的话,打开命令行,输入如下命令:
1 | ssh-keygen -t rsa –C “youremail@example.com” |
如果一切顺利的话,可以在用户主目录里找到.ssh目录,里面有id_rsa和id_rsa.pub两个文件,这两个就是SSH Key的秘钥对,id_rsa是私钥,不能泄露出去;id_rsa.pub是公钥,可以放心地告诉任何人。
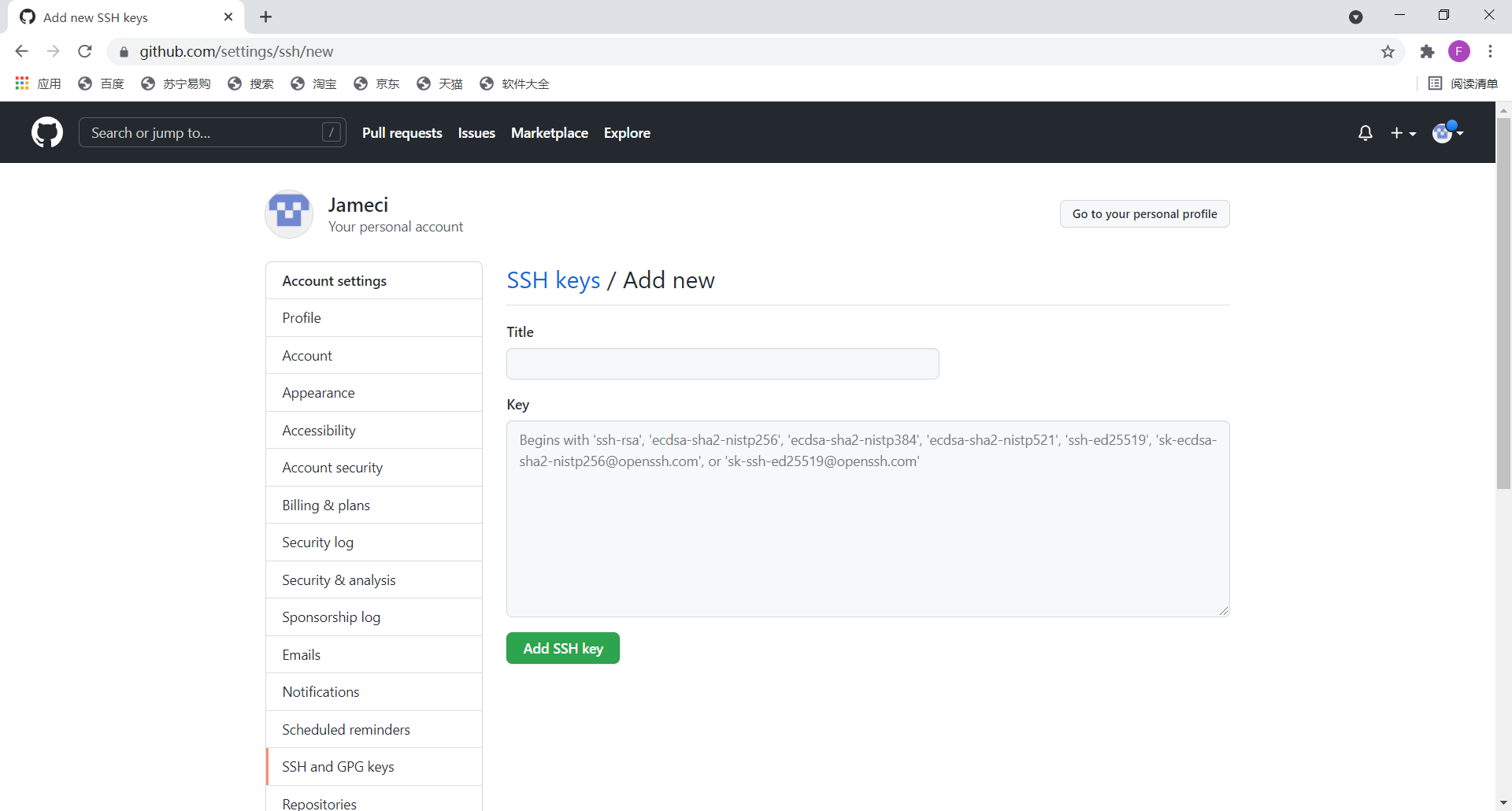
打开id_rsa.pub,复制里面的内容,登陆GitHub,打开“Account settings”,“SSH Keys and GPG keys”页面,然后,点“New SSH Key”,填上任意Title,在Key文本框里粘贴id_rsa.pub文件的内容即可。
创建仓库
首先,登陆GitHub,然后,在右上角找到“Create a new repo”按钮,创建一个新的仓库
然后起一个项目名
来到这个项目的主页
可以看到主页提供了两种和本地仓库关联起来的方式
方法一:
把本地已有的同名Git仓库和GitHub上的仓库关联起来
我们在本地新建了一个名为Gittest的文件夹,之后执行
1 | git init |
将Gittest文件夹设置为Git仓库
然后添加文件,比如我们新写了一个hello.txt:
执行本地仓库的操作:
1 | git add hello.txt |
到此为止已经提交到了本地仓库,接下来我们把本地仓库和远程仓库联系起来,执行:
1 | git remote add origin git@github.com:MachinePlay/Gittest.git |
把上面的MachinePlay替换成你自己的GitHub账户名,否则,你在本地关联的就是的MachinePlay的远程库,关联没有问题,但是推送是推不上去的,因为SSH Key公钥不在他的账户列表中。
添加后,远程库的名字就是origin,这是Git默认的叫法,也可以改成别的,但是origin这个名字一看就知道是远程库
下一步,就可以把本地库的所有内容推送到远程库上
1 | git push -u origin master |
由于远程库是空的,我们第一次推送master分支时,加上了-u参数,Git不但会把本地的master分支内容推送的远程新的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以简化命令。
此后git add git commit-m之后 就可以使用
1 | git push origin master |
就可以把自己的代码上传到远程仓库了。
方法二:
使用Git clone直接从远程仓库克隆下来
前面我们讲了先有本地库,后有远程库的时候,如何关联远程库。
现在,假设我们从零开发,那么最好的方式是先创建远程库,然后,从远程库克隆。
首先,登陆GitHub,创建一个新的仓库,名字叫Gittest
每个仓库都有一个地址:
我们在本地使用git clone直接把远程仓库克隆下来。
1 | git clonegit@github.com:MachinePlay/Gittest.git |
查看远程库信息
1 | git remote -v |
删除远程库
1 | git rm 远程库名 |