A*
POJ1077_Eight
据说这道题是不做人生就不完整的典中典
看到这个9Puzzle,我突然想起了隔壁MasterMa努力两周不眠不休的16Puzzle
幸好我没选上人工智能……
描述
求解八数码问题,并用“lrud”来描述空格子移动的方向,输出移动次数最少的解。
思路
A* 算法,设置启发函数为每个格子到其目标格子的曼哈顿距离,记录当前puzzle的状态,包括当前每个数的位置,已经移动的步数等。
由于每个状态可能会被多次遍历到,但实际上这个状态只有第一次出队列时是有效的,所以我们需要记录每个状态是否已经被访问过,为了节省空间,可以使用康托展开或者哈希的方法。
本题需要记录结果,所以每个状态还需要保存上一个状态的编号。
康托展开
给排列编号的方法,其含义可以理解为有多少个字典序小于这个排列的排列数。
1 | int transfer(int a[]){ |
解决
1 |
|
POJ2449_Remmarguts’ Date
描述
从前,有一个UDF王国,这个王国有N个车站,并且有M条路,每条路必须从车站出发,而且路的终点也必须是车站。
每条路都是单行道。
从不同的路的一端走向另一端的长度可能是不同的。
UDF王国有一个王子。有一天公主和王子需要会谈,但实际上公主不想去,于是她想恶心一下王子,派人去跟王子说,会谈的时候,王子必须走第k近的路到达,公主才会满意。
王子虽然觉得公主在臊皮,但色迷心窍,他不得不去。
王子会从S点出发,到T点开会,所谓第k近的路,就是把王子所有可以走的路线排列出来,找到长度为第k小的那条。实际上如果有圈的话王子可以不停地绕圈,路线的个数可能是无限的。
现在需要求出第k近的路有多长。
数据范围
车站数1 <= N <= 1000, 道路数0 <= M <= 100000
每条路的权值1 <= W <= 100
1 <= K <= 1000
思路
我们可以采用BFS从初始点出发,每次走一步。这样,我们需要维护一个状态为当前所在位置的队列。
但由于不同的路段权值不同,有的路走一步可能相当于其他路走好几步,所有我们应该每次取出状态集合中已经移动距离最小的状态,在最小的状态下走一步。
再进一步,使用A* 的思想,预计某个状态未来到达T点时需要走多少步,预计函数记为f,f的值加当前已经移动的距离作为取出状态优先级的标准。
本题的启发函数该如何选择呢?考虑到每个状态都是表示王子走到某个车站上去了,该状态未来的消耗在于他在这个车站向T点走的消耗,由于启发函数具有小于真正结果的特性,所以我们不妨使用每个点到T点的最短距离作为启发函数。
这就需要使用Dijkstra算法来进行初始化。
由于本题还是个有向图,这里要的是到终点的最短路,所以还得再建一个反的图。
鉴于状态很多,并且有可能是无限的,我们必须设定一个界,好准时刹车,找到答案了就停下来。我们考虑到我们最终只需要找到k条路径,它们从S点出发,到T点结束。所以我们可以记录T点在状态中出现的次数,每一次出现一定是找到了一条路。为了更加高效的进行剪枝,我们考虑到每个车站顶多会有k条路从这里出发,换句话说,每个车站顶多会被访问k次,所以对于每个车站的第k + 1次访问,我们之间去掉。
这题还是很不好写的,差点被这题打击了信心。我最开始的思路是:每两条路径之间的长度差不会超过所有边的和,所以一旦发现当前状态的预计值已经大于所有边之和,就返回。同时设置的界为搜索到当前集合中最好的状态也小于我已经找到的第k状态就返回,结果是没过,有空我会再试着改一改最初的思路。我因为这个题耗费了十个小时。
回想起大一参加的camp,经常有人爆搜+剪枝过掉本想考其他知识点的题。不得不说,搜索真是一种既有暴力又有精巧,又透着丝丝玄学的算法。
但真的难,正因为什么剪枝啦,启发函数啦,都似乎可以随心所欲,反倒是无迹可寻了。
解决
1 |
|
IDA*
POJ3460_Booksort
描述
有一个书架,通过把一列连续的书取出来,然后保持内部的顺序不变,插入到剩下的序列的任意两本书之间的方法,求五步之内能否把书排好序。如果能,输出最小步数。
思路
IDA* 算法,没想出来的时候觉得很发散,觉得这题很不着边际,结果发现其实很朴素:如果把每一本书后面的书的编号看成是这本书的后继,那么每一步顶多改变三本书的后继。对于排好序的书架,每本书的后继都是它的编号加一,这样,统计后继不是编号加一的书数目,如果对于当前状况,这个数目大于3倍剩下的步数,则直接返回。
顺带一提,这题模拟放书,刚开始感觉好难写,实际上就是个暴力模拟。。。
解决
1 |
|
POJ2286_The Rotation Game
描述
如图,井字形棋盘上有8个1,8个2,8个3,要求通过A,B,C,D,E,F,G,H这8种操作让井字中间的8个格的数字一样。
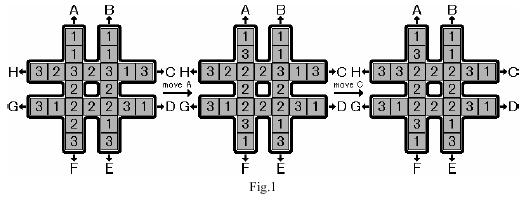
思路
IDA* ,启发函数取井字中部最多的数的个数。
这题我用了二进制位来压缩状态,但好像维护起来太复杂了……
还有一点就是没看到当有多个解时输出字典序最小的。
解决
1 |
|
CH2901_靶形数独
这题是我独立完成的,然而代码跑的比其他人都快
描述
小A和小B是一对天才儿童,有一天,这两个好兄弟决定用数独一决高下,分清谁才是老大。但由于这两兄弟太顶了,一般的数独根本就是小儿科,所以要求在解数独之后计算出数独的得分,谁的分高谁赢。
数独的得分是这样算的:最中间的数字×10,然后它周围的一圈数字×9,再向外扩展一圈×8,最外面一圈×5。换句话说,越大的数放的越靠近中心越好。
思路
IDA* 启发函数这样计算:如果某个位置的数已经确定,就直接乘以权值然后加到结果里,如果没确定,那就乘以最大可能的值。
然后解数独部分还是使用老一套:
1 使用81个二进制数来存放可能填入该位置的值
2 使用81个整数来存放每个位置还有几种可能
3 使用assign函数来为某个位置赋值,assign函数的执行过程是:先为这个位置赋值,然后使用remove函数来移出同一行,同一列,同一九宫格的所有位置的相应的可能性。如果remove函数报错,assign也报错
4 remove函数为相应位置移除可能性,如果某个位置的可能性全被移除,报错。如果某个位置的可能性只有一种,调用assign函数为其赋值,如果assign报错,remove报错
5 dfs时使用启发函数判断这个状态还有没有更新结果的机会,如果没有,回溯
6 dfs时优先遍历可能性最小的格,为其赋值并继续dfs
解决
1 |
|