K8s全称为Kubernetes,也称Kube
容器技术
容器技术是一种虚拟化技术。
虚拟机的缺点
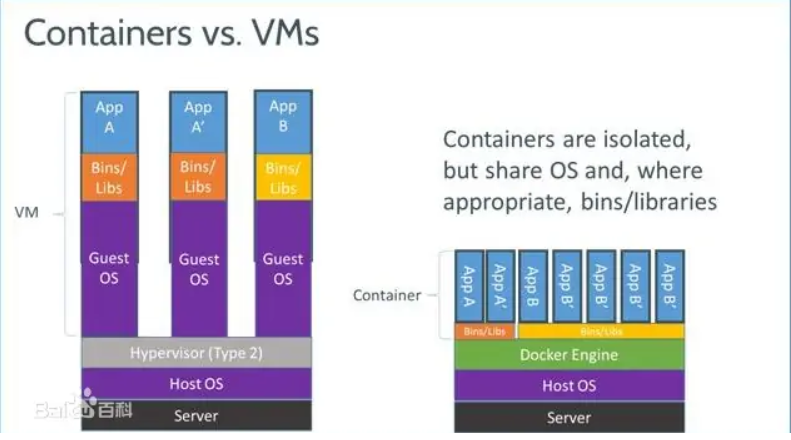
在早期,人们普遍使用虚拟机来进行远程服务器上资源的共享。虚拟机有一个特点,即每个虚拟机实例都能够运行任何其所支持的操作系统,而不受其他实例的影响。这导致了所有虚拟机必须加载操作系统的完整副本和其中大量的应用程序。
这严重影响了性能。如每种操作系统和应用程序堆栈都需要使用DRAM。对于多个运行简单应用程序的小型虚拟机实例来说,这种方式可能产生很大的系统开销,降低性能表现。加载并卸载这些堆栈镜像需要花费很长时间,并且还会增加容器技术服务器的网络连接数量。对于极端情况来说,如果用户在上午9点同时启动上千台虚拟桌面,还有可能导致网络风暴的发生。
部署虚拟服务器的目的之一在于快速创建新的虚拟机实例。然而从网络存储当中复制镜像需要花费大量时间,这些操作会延长启动过程,无疑会限制系统灵活性。
容器
一个容器镜像是一个可运行的软件包,其中包含了一个完整的可执行程序,包括代码和运行时需要应用、系统库和全部重要设置的默认值。
应用程序通过使用容器与底层的宿主机架构解耦。如下图所示,我们可以利用底层机器在容器引擎之上运行多个容器。这促进了容器在各种操作系统和云场景中的部署。
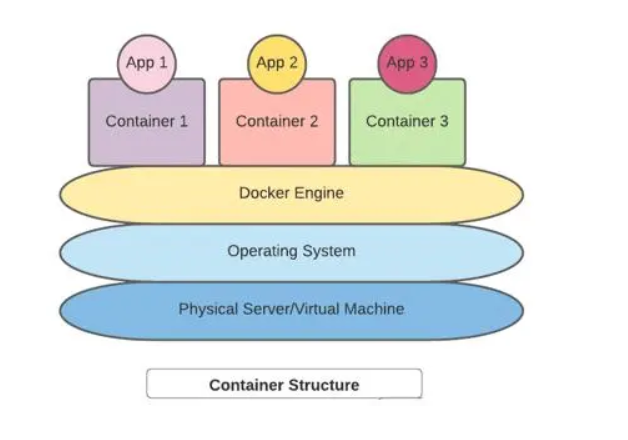
容器技术的核心就是通过对资源的限制和隔离把进程运行在一个沙盒中。并且这个沙盒可以被打包成容器镜像(Image),移植到另一台机器上可以直接运行,不需要任何的多余配置。其中docker是容器技术的事实标准。
Docker
Docker是PaaS提供商dotCloud开源的一个基于LXC(一种内核虚拟化技术,可提供轻量级的虚拟化)的高级容器引擎,源代码托管在Github上, 基于go语言并遵从Apache2.0协议开源。
Docker使用客户端-服务器(C/S)架构模式,使用远程API来管理和创建Docker容器。Docker容器通过Docker镜像来创建。容器与镜像的关系类似于面向对象编程中的对象与类。
Docker采用C/S架构Docker daemon作为服务端接受来自客户的请求,并处理这些请求(创建、运行、分发容器)。客户端和服务端既可以运行在一个机器上,也可通过socket或者RESTful API来进行通信。
Docker daemon一般在宿主主机后台运行,等待接收来自客户端的消息。Docker客户端则为用户提供一系列可执行命令,用户用这些命令实现跟Docker daemon交互。
容器编排和K8s
举一个例子:如果两个应用调用关系比较紧密,那么我们希望运行时将它们部署在同一台机器上,从而提升服务之间的通信效率。
在应用和容器较多的情况下,自然希望这一工作能够由某个管理程序自动执行。这就是容器编排。
Docker镜像一举解决了应用打包和发布的技术难题。但Docker作为单一的容器技术工具并不能很好地定义容器的“组织方式”和“管理规范”,难以独立地支撑起生产级大规模容器化部署的要求。
容器编排是Kubernetes的核心技术能力,Pod是Kubernetes中最基础的编排对象,Pod运行在一个被称为节点(Node)的环境中,这个节点既可以是物理机,也可以是私有云或者公有云中的一个虚拟机,通常一个节点上运行几百个Pod。在每个Pod中都运行着一个特殊的被称为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此它们之间的通信和数据交换更为高效,在设计时我们可以利用这一特性把密切相关的服务进程放入同一个Pod中。
一般来说,Docker被视作容器引擎,而Kubernetes则属于较上层的编排调度层。但实际上,Kubernetes也支持其它的容器实现工具,并不完全依赖Docker。
标准的一个K8S集群最多可以管理大概5000台服务器,平均每台服务器上跑着30-40个容器,算下来差不多20万个容器。
K8s介绍
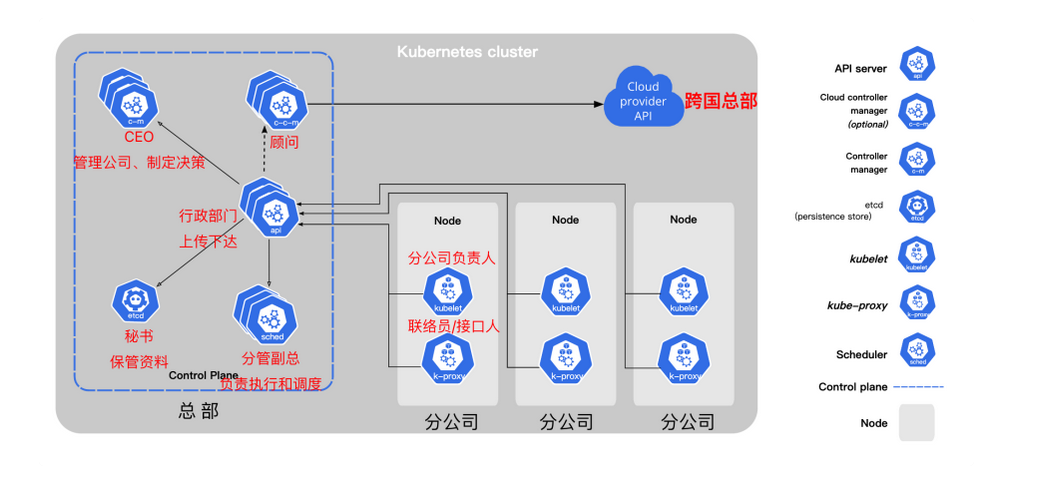
K8s架构
控制平面(Control Plane)
控制平面组件会为集群做出全局决策,比如资源的调度、检测和响应集群事件。
分为四部分
kube-apiserver
提供与Kubernetes 集群交互的API
kube-scheduler
集群状况是否良好?如果需要创建新的容器,要将它们放在哪里?这些是调度程序需要关注的问题。
scheduler调度程序会考虑容器集的资源需求(例如 CPU 或内存)以及集群的运行状况。随后,它会将容器集安排到适当的计算节点。
etcd
etcd是一个键值对数据库,用于存储配置数据和集群状态信息。
kube-controller-manager
控制器负责实际运行集群,controller-manager控制器管理器则是将多个控制器功能合而为一,降低了程序的复杂性。
controller-manager包含了这些控制器:
● 节点控制器(Node Controller):负责在节点出现故障时进行通知和响应
● 任务控制器(Job Controller):监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
● 端点控制器(Endpoints Controller):填充端点(Endpoints)对象(即加入 Service 与 Pod)
● 服务帐户和令牌控制器(Service Account & Token Controllers):为新的命名空间创建默认帐户和 API 访问令牌
Node组件
节点上就两个组件
kubelet
kubelet 会在集群中每个节点(node)上运行。 它保证容器(containers)都运行在 Pod 中。
当控制平面需要在节点中执行某个操作时,kubelet 就会执行该操作。
kube-proxy
kube-proxy 是集群中每个节点(node)上运行的网络代理,是实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点网络规则和转发流量,实现从集群内部或外部的网络与 Pod 进行网络通信。
kubeadm配置简单model
先装docker
1 | sudo apt update |
准备工作
1 | # 禁用交换分区(在旧版的 k8s 中 kubelet 都要求关闭 swapoff ,但最新版的 kubelet 其实已经支持 swap ,因此这一步其实可以不做。) |
Master节点的配置
1 | # 安装基础环境 |
部署Master
创建kubeadm-config.yaml
kubeadm config print init-defaults > kubeadm-config.yaml
改了这些地方:
advertiseAddress: 改成本机ip
name: 改成了master
imageRepository: 改成了registry.cn-hangzhou.aliyuncs.com/google_containers
拉取镜像
docker pull用来拉取镜像,docker tag用于打标签
先试试kubeadm config images pull能不能成功,这用来测试和”k8s.gcr.io”, “gcr.io”, “quay.io”的连接
若不行,首先查看kubeadm config 依赖的images有哪些:
1 | #查看kubeadm config所需的镜像 |
然后从国内镜像拉取这些镜像(有些是可以直接拉取的,比如 k8s.gcr.io/coredns/coredns:v1.8.6)
1 | #从国内镜像拉取 |
#将拉取下来的images重命名为kubeadm config所需的镜像名字
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.8 k8s.gcr.io/kube-apiserver:v1.23.8
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.8 k8s.gcr.io/kube-controller-manager:v1.23.8
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.8 k8s.gcr.io/kube-scheduler:v1.23.8
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.8 k8s.gcr.io/kube-proxy:v1.23.8
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6 k8s.gcr.io/pause:3.6
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0 k8s.gcr.io/etcd:3.5.1-0
docker tag coredns/coredns:1.8.6 k8s.gcr.io/coredns/coredns:v1.8.61
2
3
4
5
6
7
8
9
10
11
12
13
14
15
### 初始化
kubeadm init --config kubeadm-config.yaml
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
记住node加入集群的命令 上面kubeadm init执行成功后会返回给你node节点加入集群的命令,等会要在node节点上执行,需要保存下来,如果忘记了,可以使用如下命令获取。
kubeadm token create --print-join-command
## 部署节点
安装基础环境
apt-get install -y ca-certificates curl software-properties-common apt-transport-https curl
curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
执行配置k8s阿里云源
vim /etc/apt/sources.list.d/kubernetes.list
#加入以下内容
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
执行更新
apt-get update -y
安装kubeadm、kubectl、kubelet
apt-get install -y kubelet=1.23.1-00 kubeadm=1.23.1-00 kubectl=1.23.1-00
阻止自动更新(apt upgrade时忽略)。所以更新的时候先unhold,更新完再hold。
apt-mark hold kubelet kubeadm kubectl1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
这里加入集群的命令每个人都不一样,可以登录master节点,使用kubeadm token create --print-join-command 来获取。获取后执行如下。
kubeadm join 172.31.186.200:6443 --token fmty0x.5v15q0m9nzwd8lcy --discovery-token-ca-cert-hash sha256:604205e4fd92840baa05977e1770cefcd45ebae251761d94144572f66b1f4e1d
如果此处报错,则需要重启 即可
kubeadm reset
加入成功后,可以在master节点上使用kubectl get nodes命令查看到加入的节点
五、部署 Calico(master机器)
以上步骤安装完后,机器搭建起来了,但状态还是NotReady状态,如下图,master机器需要安装Calico。
kubectl apply -f https://docs.projectcalico.org/v3.21/manifests/calico.yaml
安装完成后需要等待k8s重新拉起节点
六、完成
在master执行,即可看到节点已为Ready状态
kubectl get nodes
# 手动配置一个简单的model
预先准备了两台机器
hz01ddd,计划让hz01为master节点,ddd为普通node
## 配置服务端环境
### 安装ETCD
第一步,准备证书
(要用到哪些证书 https://kubernetes.io/zh-cn/docs/setup/best-practices/certificates/)
#### 数字证书的作用
证书是可信任的机构颁发的,即CA认证中心,不同的CA认证中心结构类似于树形。根CA认证中心可以授权多个二级的CA认证中心,同理二级CA认证中心也可以授权多个3级的CA认证中心
父CA认证中心会给子认证中心发一个数字证书,和属于自己的公钥私钥
数字证书就是网络上数字实体的身份证,其它实体通过验证数字证书来确认该实体的可靠性(通过向发给该实体证书的CA认证)
之后发报文时,数字证书用来给报文签名,确保每个报文都是该实体发的
证书所有者自己保存私钥,把公钥放在自己的数字证书内
发送报文时,发送方用一个哈希函数从报文文本中生成报文摘要,然后用发送方的私钥对这个摘要进行加密,这个加密后的摘要将作为报文的数字签名和报文一起发送给接收方,接收方首先用与发送方一样的哈希函数从接收到的原始报文中计算出报文摘要,接着再公钥来对报文附加的数字签名进行解密,如果这两个摘要相同、那么接收方就能确认该报文是发送方的
#### 怎么生成数字证书
证书有四种类型
自签名证书:又称为根证书,是自己颁发给自己的证书,即证书中的颁发者和主体名相同。申请者无法向CA申请本地证书时,可以通过设备生成自签名证书,可以实现简单证书颁发功能。设备不支持对其生成的自签名证书进行生命周期管理(如证书更新、证书撤销等)
CA证书: CA自身的证书。如果PKI系统中没有多层级CA,CA证书就是自签名证书;如果有多层级CA,则会形成一个CA层次结构,最上层的CA是根CA,它拥有一个CA“自签名”的证书。申请者通过验证CA的数字签名从而信任CA,任何申请者都可以得到CA的证书(含公钥),用以验证它所颁发的本地证书。
本地证书:CA颁发给申请者的证书。
设备本地证书:设备根据CA证书给自己颁发的证书,证书中的颁发者名称是CA服务器的名称。申请者无法向CA申请本地证书时,可以通过设备生成设备本地证书,可以实现简单证书颁发功能。
要确保:
所有操作全部用root使用者进行
所有节点彼此网络互通
master1 SSH 登入其他节点为 passwdless,在任何一个机器或者任何一个user下使用命令ssh-keygen -t rsa生成一个秘钥对,$user_home/.ssh/id_rsa & id_rsa.pub,然后将id_rsa.pub里面的内容拷贝你想无密码登录到的机器和用户下的.ssh/authorized_keys文件里,并且chmod700,你就可以无密码登录了。结论就是不管这对秘钥对(私钥、公钥)是在哪里生成的,只要生成了,你就可以在任何地方使用它
所有防火墙与 SELinux 已关闭。如 CentOS:
# K8s新建pod
## 新建pod
查看pod的命令:
kubectl get pod -n default1
2
3
4
5
6
7
首先写一个资源清单:
例子:
testpod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: nginx-containers
image: nginx:latestkubectl apply -f testpod.yaml1
2
3
然后执行命令:1
2
3
4
5
6
7
正常情况下就创建成功了
## 在pod里执行命令
查看pod信息$ kubectl describe pods/<pod-name>$ kubectl describe pods <pod-name>1
- 执行Pod的data命令,默认是用Pod中的第一个容器执行
$ kubectl exec <pod-name> data - 指定Pod中某个容器执行data命令
$ kubectl exec <pod-name> -c <container-name> data - 通过bash获得Pod中某个容器的TTY(终端?),相当于登录容器
$ kubectl exec -it <pod-name> -c <container-name> bashdocker attach1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# docker
## 镜像
Docker 主机安装之后,本地并没有镜像。
docker image pull 是下载镜像的命令。镜像从远程镜像仓库服务的仓库中下载。
默认情况下,镜像会从 Docker Hub 的仓库中拉取。docker image pull alpine:latest 命令会从 Docker Hub 的 alpine 仓库中拉取标签为 latest 的镜像。
Linux Docker 主机本地镜像仓库通常位于 /var/lib/docker/<storage-driver>,Windows Docker 主机则是 C:\ProgramData\docker\windowsfilter。
可以使用以下命令检查 Docker 主机的本地仓库中是否包含镜像。
$ docker image ls
只需要给出镜像的名字和标签,就能在官方仓库中定位一个镜像(采用“:”分隔)。从官方仓库拉取镜像时,docker image pull 命令的格式如下。
docker image pull <repository>:<tag>
## docker登录到容器中
登录命令docker exec1
2
3
4
5
6
7
登录之后就可以在容器里进行任何操作
ctrl+p+q,就可以安全退出了
其缺陷是所有人都只能用一个,别人输的命令你也能看到`
- 执行Pod的data命令,默认是用Pod中的第一个容器执行
执行一条命令,可以用–help查看其详细信息,可以执行/bin/bash来运行命令,不存在attach的问题
如果运行的容器中开启了ssh服务,也可以用远程ssh的方式