爬虫概述
数据的来源:
企业生产的用户数据
数据管理咨询公司
政府/机构公开数据
第三方购买数据
爬虫获取网络数据
基本用途
- 获取数据分析/人工智能的数据
- 爬取其他社区用户信息,作为社交软件的冷启动
- 舆情监控
- 监控商业竞争对手
- 12306抢票
- 选课
- 刷票
- 短信轰炸
- 理论上浏览器能做的爬虫都能做
设计思路
网页的三大特征:
- 唯一的URL
- 都使用HTML来描述页面信息(还有CSS/JS,HTML骨架,CSS皮肤,JS功能)
- 都使用HTTP/HTTPS来传输HTML信息
爬虫:
- 确定要爬的URL地址(网页分为静态——没有任何交互,和动态——数据是通过进一步请求获取到)
- 通过HTTP/HTTPS协议获取界面
- 从界面中筛选有用的数据
两类爬虫
通用爬虫针对于搜索引擎,聚焦爬虫针对于某个网站
聚焦爬虫向指定的urllist发生请求,得到响应,提取深层url直到找到想要的数据,之后筛选信息并存储
也可以按照是否获取数据分为功能性爬虫和获取数据的爬虫
工具
curl
安装apt-get curl,依赖openssl,openssl-dev
直接使用curl + url发送请求:
url是你想要请求的网址,可以简单理解为一个在命令行里的浏览器
在浏览器的网络一栏可以看到详细的请求信息
使用curl时,默认发起的是get请求
参数
-A 设置user-agent,即设置使用的浏览器种类
-X 设置使用的请求方法
可以用httpbin.org来测试,是用于学习http的一个网站
-I 只返回请求的头信息
-d 以POST方法请求url并发送相应的参数
@文件名可以发送写入到文件里的参数
-O参数,下载并以远程的文件名保存
-o参数,以自定义的文件名保存

-L参数,跟随重定向请求3xx跳转
-H参数,指定接收的格式

-k参数,允许发起不安全的ssl请求
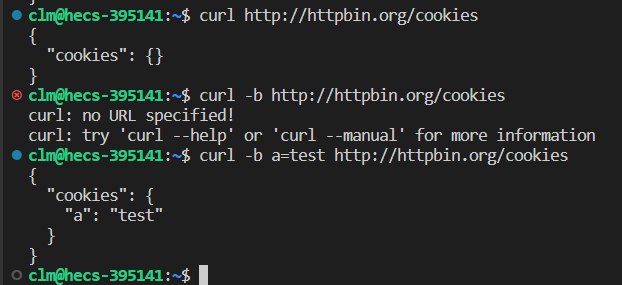
-b参数,发起带cookie的请求
-v参数,显示连接过程中的所有信息
使用curl做简单的爬虫
curl命令 | grep -E ‘正则表达式’
获取自己的外网ip地址:
1 | curl http://httpbin.org/get | grep -P '\d+\.\d+\.\d+\.\d+' | cut -d '"' -f 4 |
alias命令——设置别名
1 | alias myip="curl http://httpbin.org/get | grep -P '\d+\.\d+\.\d+\.\d+' | cut -d '\"' -f 4" |
之后使用myip就可以了
wget
专门下载的命令
使用方法:wget 资源url路径
以指定的文件名和格式下载:wget -O “指定文件名” 资源url路径
限速下载:wget –limit-rate=速率(如20k,3m) ……
Linux中–参数一般带值,-参数不带
断点续传:wget -c(下载大文件防止重新来)
后台下载:wget -b
指定User-agent:wget -U “Chrome”
只下载比本地更新的文件:wget -N
下载页面中所有内联资源(图片等):wget -p
递归下载所有链接:wget -r -l 深度(数字,无限则是inf)
镜像这个网站:wget –mirror,等于开启了时间戳,无限深度递归wget -r -N -l inf –no-remove-listing
转换链接为本地链接:–convert-links
不检查证书:–no-check-certificate
下载网站到本地:
1 | wget -c --mirror -U "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36" -p --convert-links --no-check-certificate "jameci.github.io" |
httpie
To Be Complete
Postman
To Be Complete
Python爬虫
urllib(已弃坑)
最基本的请求
使用urlopen请求一个对象,返回http.client.HTTPResponse类型的对象
1 | from urllib.request import urlopen |
更换User_Agent来请求
1 | import urllib.request |
Basic-Auth(没整明白)
HTTP是一个无状态协议,但有些网站是需要用户登录后操作的。客户端首次登录后,服务端会向客户端发送一个凭证,之后客户端的每个请求都会带着这个凭证
以请求服务端上的一张图片为例,如果客户端发送请求时没有带凭证,服务端就会返回如下的response:
1 | HTTP/1.1 401 Authorization Required |
在服务器返回的 Header 中会告诉客户端认证失败,获取 realm=org 的资源需要通过Basic Auth 的认证方式进行认证,也就是你要告诉服务器你是谁;这里面有几个参数:
1 | Basic:认证方式是 Basic Auth |
整个 www-Authenticate字段的值就是告诉客户端你要获取域为 org 下的图片需要通过 Basic auth的方式认证
客户端收到响应时,就会按照Basic Auth 认证方式,添加认证信息到请求头,再次发送Request,格式如下:
1 | GET /org/cat.jpg HTTP/1.1 Authorization: Basic |
其中,请求头中字段 Authorization的值就是账密信息,Basic Auth 通过如下的方式编码账密信息的:Base64(username:password)
服务器收到请求之后就会验证,验证通过就会返回相应的资源
HTTP Basic Auth 的优点很明显,就是简单,很容易就能够被支持
缺点也很明显就是 Base64编码很容易就会被破解,所以只要拦截了请求就能够获取到用户的账号和密码,安全性差
基本http认证示例:
1 | import urllib.request |
Requests
内部的实现是用了urllib,对urllib做了封装