写这篇之前,我想分享一件趣事:今天开组会的时候,师兄看到了我电脑上的Logisim,非常惊恐地问我:“你选组成原理了?”
我看出了他的潜台词,便有些不好意思:“嗯,是的”
因为我选课的时候,还真忘记这件事了——师兄当时提醒过我,还特意点了组成原理不要选,千万不要选,因为很难,很难很难
之后组会上就讲起了组成原理笑话,什么北航4大名挂之一啊,什么28个人里面只及格3个啊,什么实验是闯关制做不完根本没法往下做啊
然后师兄说,还记得2020年在图书馆的那个吗
另一位师兄抢过话头,说他舍友就在现场,那人倒下的时候,电脑屏幕上显示的就是组成原理
我挠挠头,张了张嘴,过了一会儿才说出这么一句:“真有那么难么”
所有的师兄都看着我笑了起来
老师也看着我笑了起来
连师弟也笑起来了
整个会议室充满了快活的空气
课程内容
第一节课
感觉第一节课就讲了讲概要,考核方式
体系结构其实也算老朋友了,毕竟核心课之一,当年大二学的时候还是学得挺扎实的(从指令集编码到CPU内存,除了最后一章cache没听),但确实很硬核
首先是一个问题:我们如何用计算机来解决一个具体问题?
下面给出了一个具体的问题是如何被自顶而下地抽象成电子元件的结合:

他这里放了个运行时系统,这是一种介乎编译和解释的运行方式,由编译器首先将源代码编译为一种中间码,在执行时由运行时充当解释器对其解释,感觉不是所有语言都会这样
再说一下体系结构和微体系结构,ISA是指令集体系结构,是软硬件的接口,规定了机器能实现的指令,不考虑硬件怎么实现;微体系结构是具体硬件的实现方式说明,其它的就不必多说了
学过计算机的都知道,这样的分层和抽象是我们的老朋友了。分层和抽象的好处在于上层可以不管底层是怎么实现的,无需了解其技术细节,提高解决问题的效率
那这门课要求我们了解底层,认识底层的原因是什么呢?一方面是为了设计硬件,另一方面是为了更好地写软件。设计硬件好理解,更好地写软件一方面是考虑到底层的东西,能更好地优化,精益求精,另一方面是万一遇到底层造成的错误,可以有解决的方向
一个例子
其实这么一说感觉没啥说服力,所以给了例子:
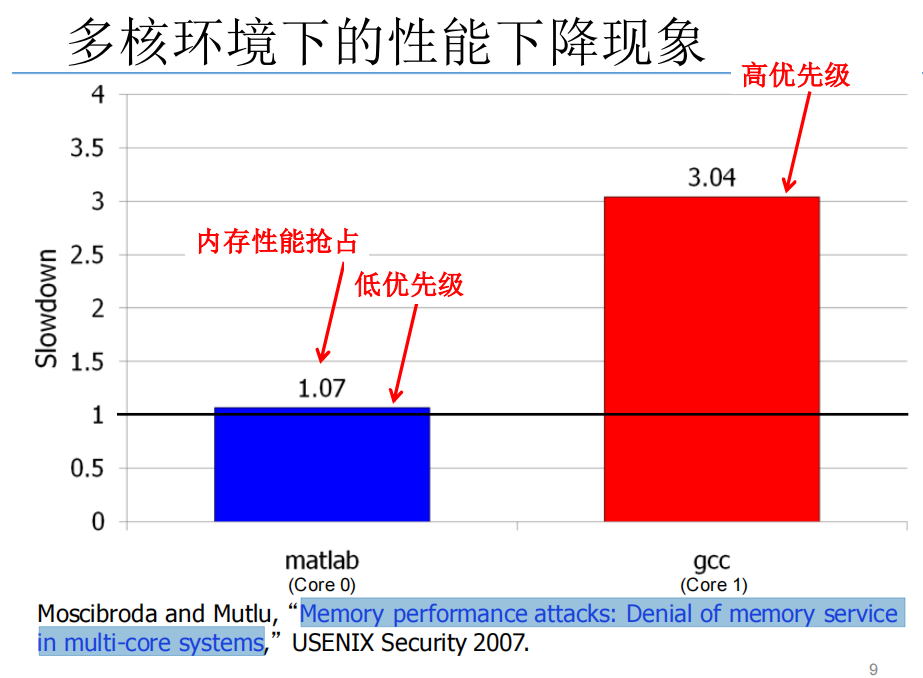
用双核机器运行gcc和matlab,相比单核情况下,matlab只是性能略有下降,而gcc性能却大幅下降
原因是他们共用DRAM存储系统(内存),其中有个行缓冲机制,matlab频繁使用数据,访存快,行命中率高,而gcc访存慢一些,行命中率低
而行命中的情况下访存速度远远大于不命中
这能得出什么呢?
如果我们在不知道这个机制的情况下去分析为什么两者会出现如此显著的性能差别,我们可能会猜测操作系统对不同的进程之间有不同的优先级,而为了解决问题,我们把gcc的优先级调高
可结果发现是徒劳的,我们可能就无计可施了
再或者,我们可以写一些内存密集型的程序,来利用这种不公平性进行内存的拒绝服务攻击——导致别人的程序性能大幅度下降
说了那么多,就是想证明,学这个是很有用的
ISA和微体系结构
ISA规定软硬件之间的接口,微体系结构是对软件开发者来说不可见的

其实我不是很明白,为什么ISA能实现功耗和温度管理,感觉这不是偏硬件的吗……

总感觉我分辨不出来

为啥加法指令的操作码和微体系结构有关?
流水线又和ISA有啥关系?
指令周期和ISA有啥关系?
似乎寄存器堆指的是所有寄存器的集合,所以有几个端口可能会影响指令集怎么实现吧……
复习指令流水线
因为作业3里提到了指令流水线,这里我已经忘得只剩概念了——尽管可以直接抄,但是会留下隐患——期末怎么办呢。所以我决定趁此机会复习一下,反正用之前袁春风老师那本书的话,指令流水线就一章
实验
开发单周期MIPS处理器
下载Logisim
https://sourceforge.net/projects/circuit/
项目刚刚打开是这样的
教程
https://vlab.ustc.edu.cn/guide/doc_logisim.html
简单概况下教程学到的东西:
如何新建与或非门,如何添加输入输出,怎么连接?
如何修改输入输出?
如何调节元件的位宽?
如何把一个模块作为另外一个模块的构件?
复习MIPS指令结构
MIPS指令是32位的,分为三种指令:R型,I型和J型
R型就是两个操作数都在寄存器,并且指定结果去哪个寄存器
op是操作码,对于所有的R型指令,操作码都是0,Rs,Rt是两个源操作数所在寄存器编号,Rd是目的寄存器
Shamt仅仅在移位操作的时候有用,其它情况下都是0
Func真正决定了R型指令的类型
I型就是其中有一个操作数是16位立即数
J型是带跳转的指令

addu的Func字段是100001,subu的是100011
ALU
找了很多本书,没找到ALU细致的描写,最后还是回到本科时候袁春风老师那本书找到的
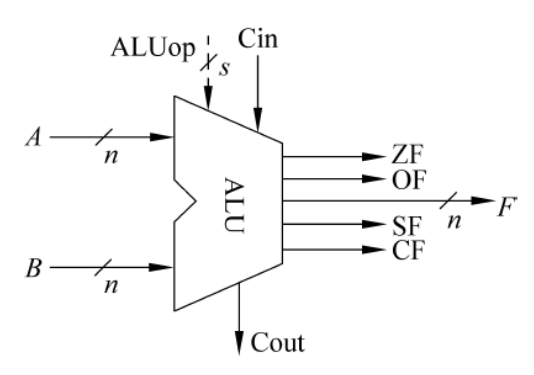
我们要实现的MIPS字长是32位,因此n=32
ALU的操作数即图中的A和B,默认都看做补码运算
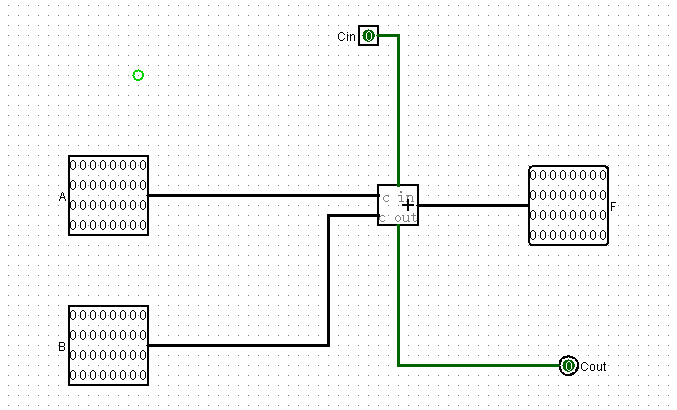
加法器
Logisim里面有自带的加法器,我们将其连接输入输出
减法器
为实现补码减法,添加减法控制信号SUBctr,当该信号为1时,说明在做减法,否则就是做加法
A-B等于A加上B的补,也就是A加上B的反再加1
为此,SUBctr信号进行1扩展和B做异或运算,然后再把SUBctr信号连接到Cin上
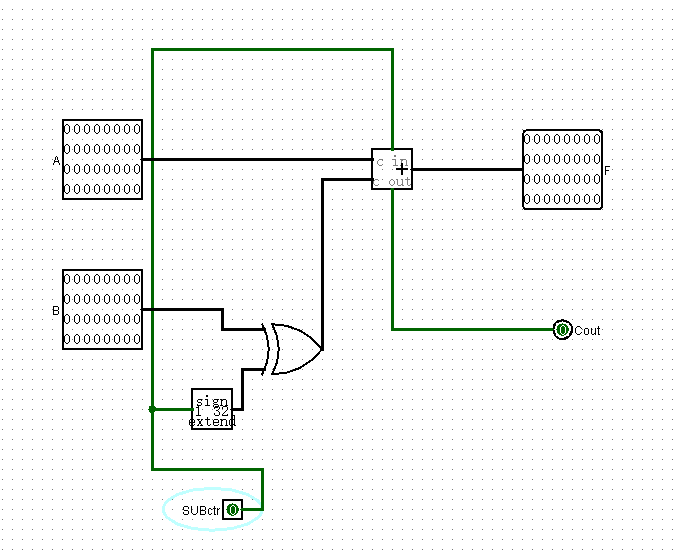
输出信号
我们需要关注ALU的信号有三个,都是一位的数字信号:
Zero,顾名思义,如果ALU运算的结果是0,该信号置1,否则为0
Overflow,溢出,补码运算时,两个负数(符号位都是1)相加得到正数,或者两个正数(符号位是0)相加得到负数,Overflow置1,否则置0
在无符号数运算时,Overflow是没有意义的
Add-Carry,进位/借位,无符号数运算时才有意义,加法时可以把之前的Cout直接看做Add-Carry。减法时,可以推导出A若小于B,则A加上B的补码是不进位的,所以减法时需要把Cout取反
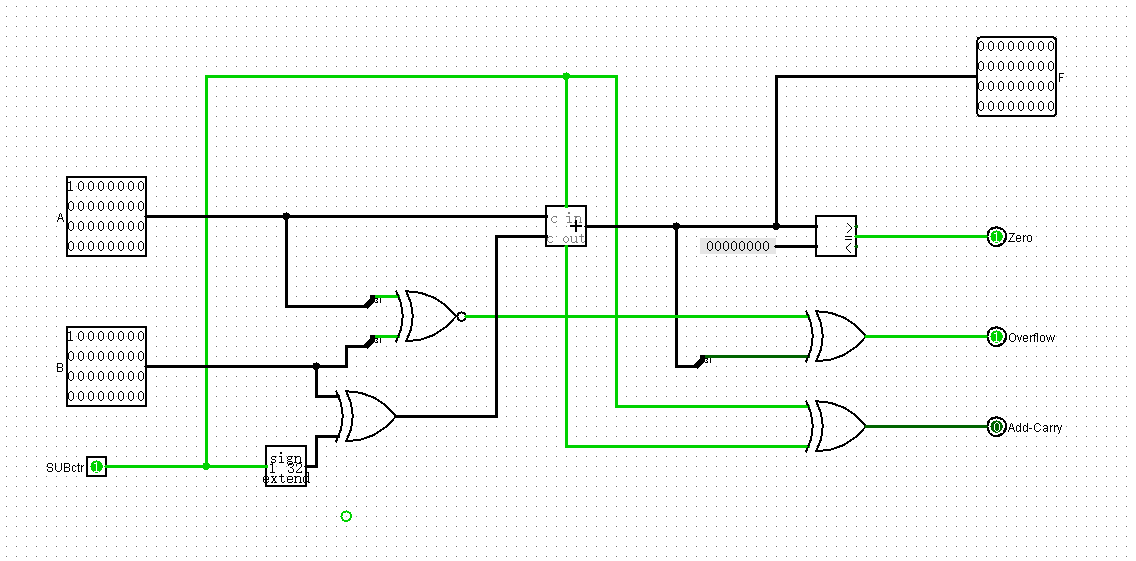
此时addu和subu其实都可以运作了
ori运算
为了实现ori,需要单独增加一个或门模块,再加一个2路选择器
此时,为了识别运算到底是使用加法器还是或门,需要一个OPctr信号
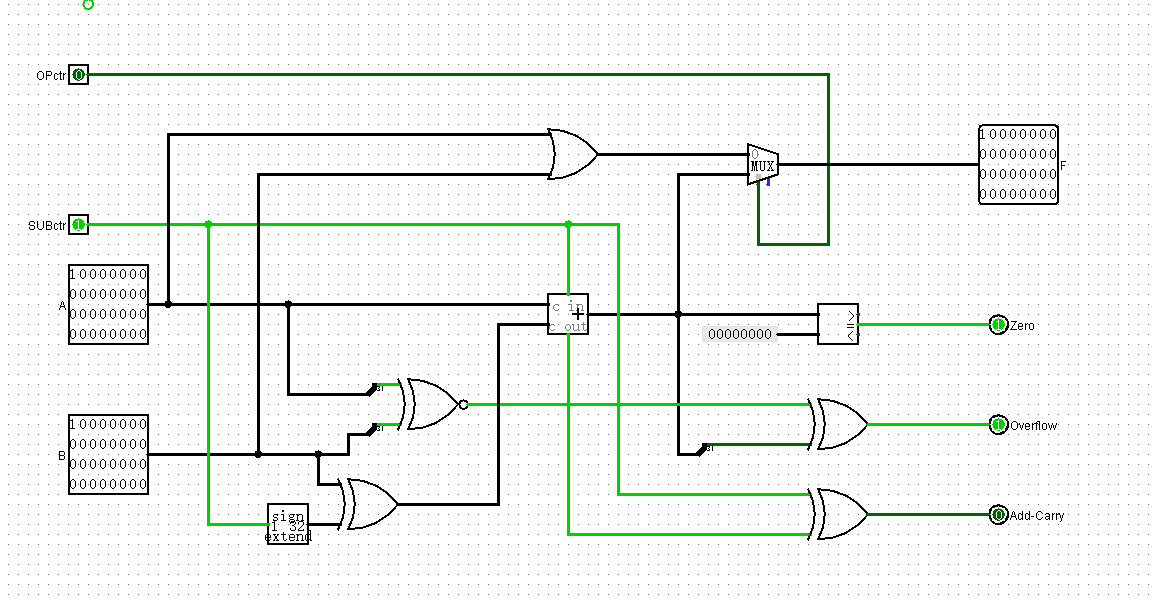
此时,OPctr是0,执行or运算,是1则执行加减法
sw和lw
这两条是访存指令,一条读一条写,主要是计算地址,使用寄存器里的地址+立即数偏移量来算
完全可以使用ALU中的加法器模块解决
lui
将16位立即数存放至指定寄存器的高16位,并将其低16位置0
同样完全将其定义为一种新运算,为此OPctr需要扩展到两位了
以运算频率,OPctr为0,代表加减,1代表or,2代表lui
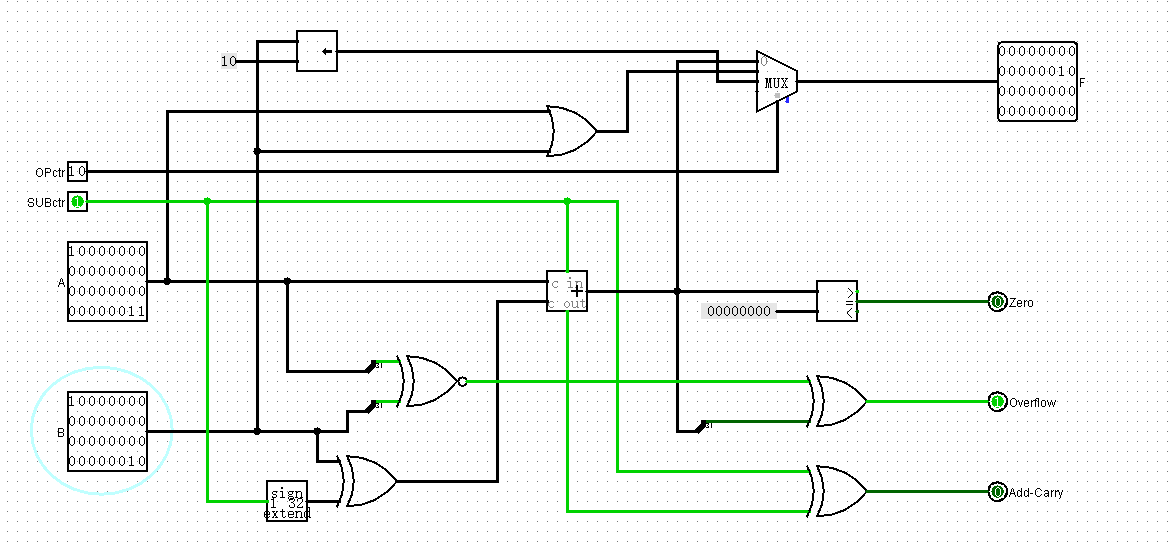
beq
beq指令会比较两个寄存器的值,它们若相等,则发生转移
转移发生时,立即数里的offset会左移两位加到pc里
ALU只需要做相等的判断,可以靠减法实现
ALU的封装
(土到极致就是潮!)
至此,ALU设计完成
修改:把Sub信号混入ALUctr
实际上,外界对ALU并不会单独输入一个SUB信号,我之前的设计是错的,这就需要重新设计一下ALU
现在ALUctr控制0是加减,1是ori,2是lui
我要改成0是加,1是减,2是ori,3是lui
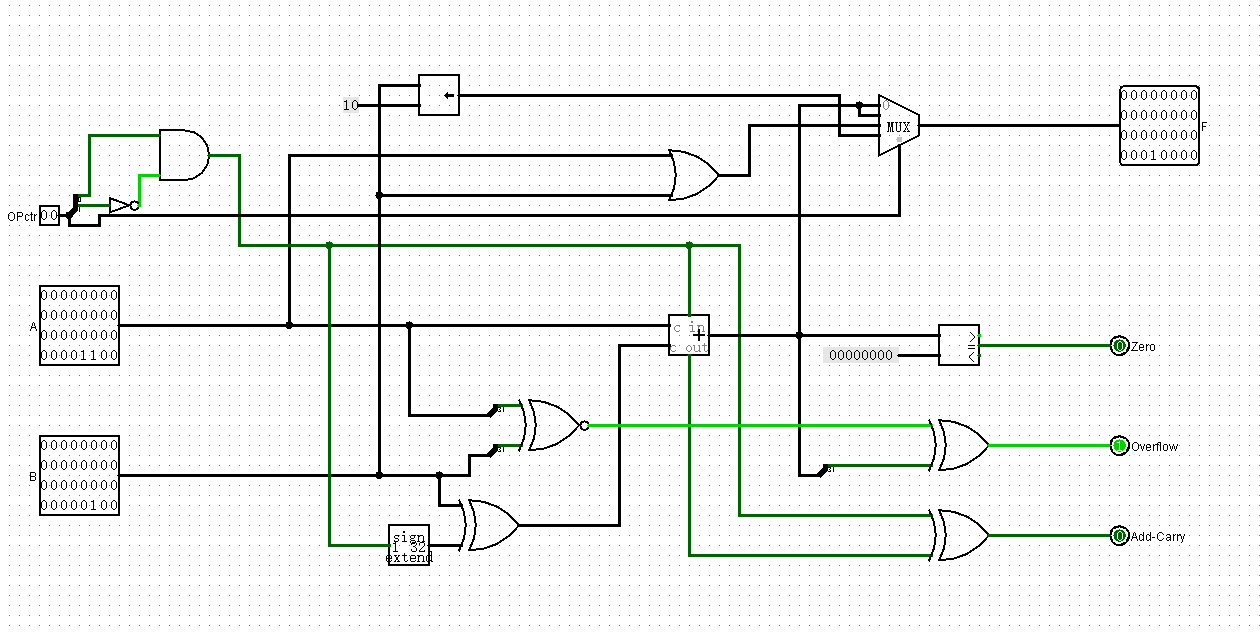
这是最好改的方法,但不是最简单的,最简单的方法应该是再加一个减法器,不过所谓改革不是向着最好的方向改,而是向着阻力最小的方向,所以我觉得我改的没问题
IFU
PC的自增
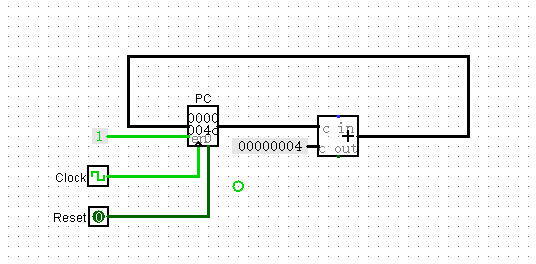
使用一个寄存器表示PC,用加法器满足PC随着时钟周期的自增
取指令
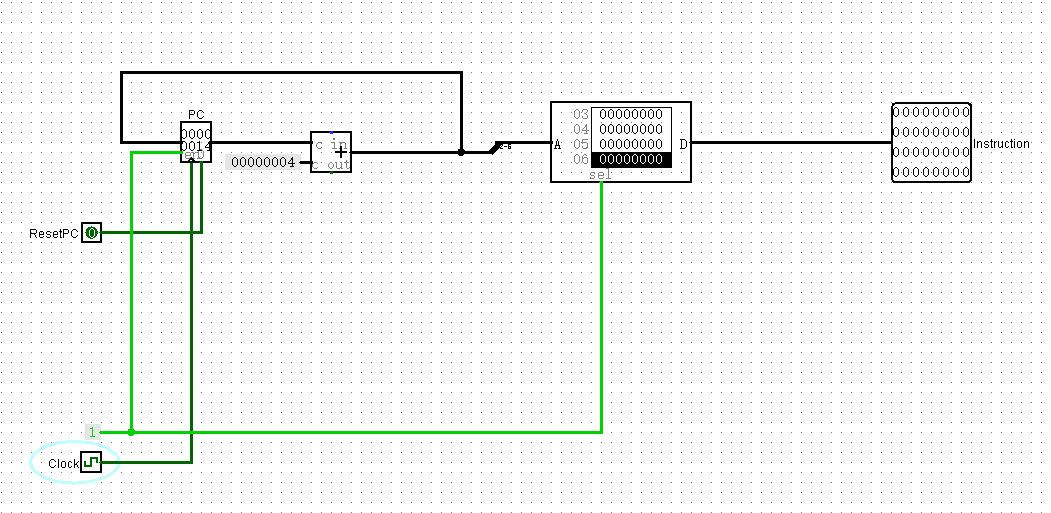
倒是挺简单,加个ROM就可以了
实现分支
指令分支的逻辑是PC加上4之后,再加上某个立即数左移两位后的值
因此要再加个加法器,并且来个分支信号和零信号共同控制二路选择器
之所以要分支和零信号共同控制,是因为beq指令就是同时有分支和零时才会跳转
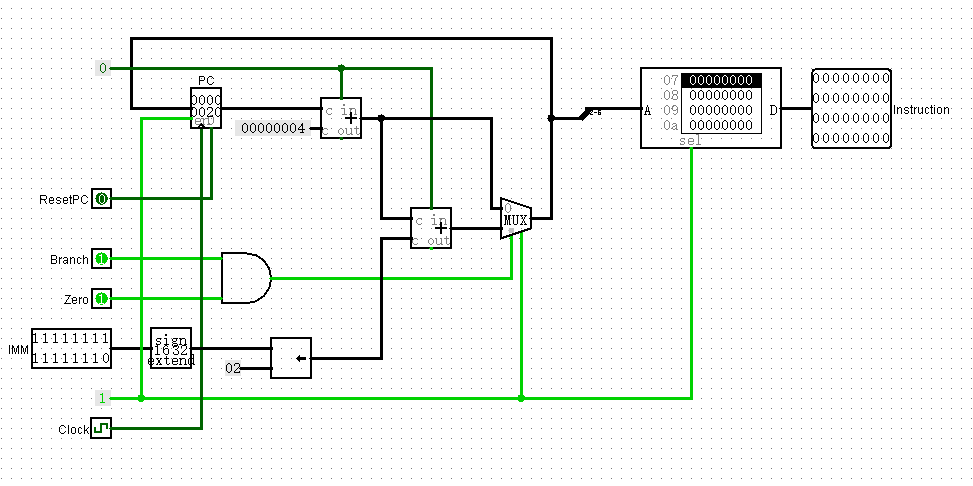
实现复位
封装IFU
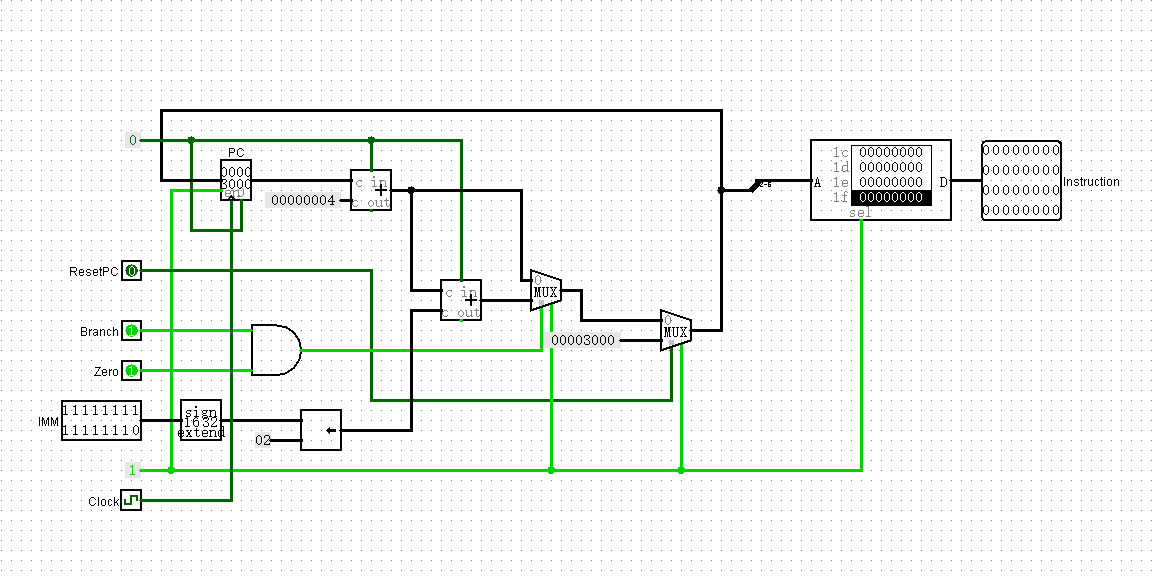
修改:IFU应该读出的是PC的值,而非下地址值
今天一打开项目,发现很多线变成蓝色了,原因是有些元件把three-state打开了。关掉之后花费了很长时间
GPR
寄存器堆要求读写异步,看了一下好像不是什么难题——因为有支持异步读写的寄存器部件
问题是怎么实现给个地址然后读写对应位置的寄存器
一下子就想到了阵列——搞32个寄存器排开,然后把地址信号分线译码
但太乱了,我又想到了更好的方法,如下:
先用两个寄存器组成地址长度只有1的寄存器堆:
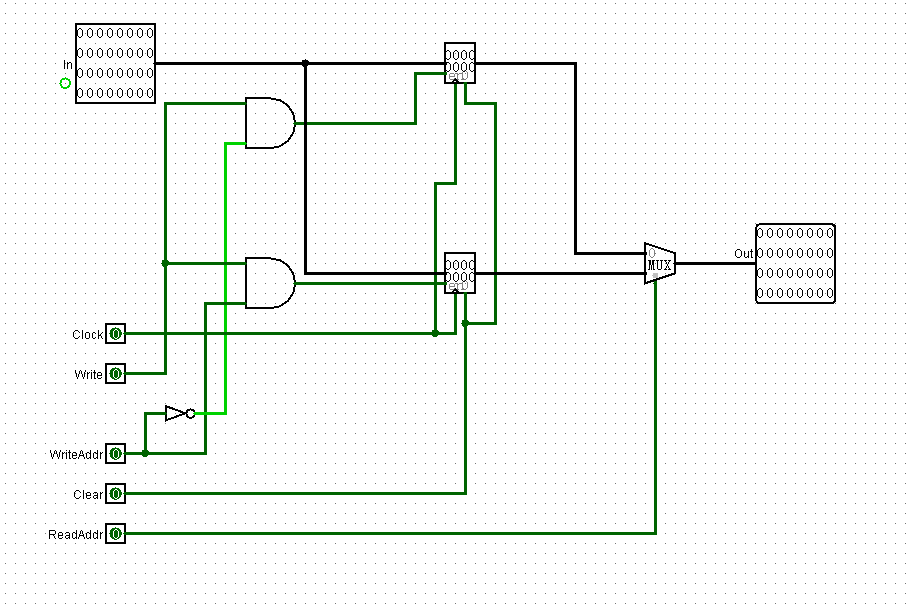
之后用封装好的GPR2组成GPR4:
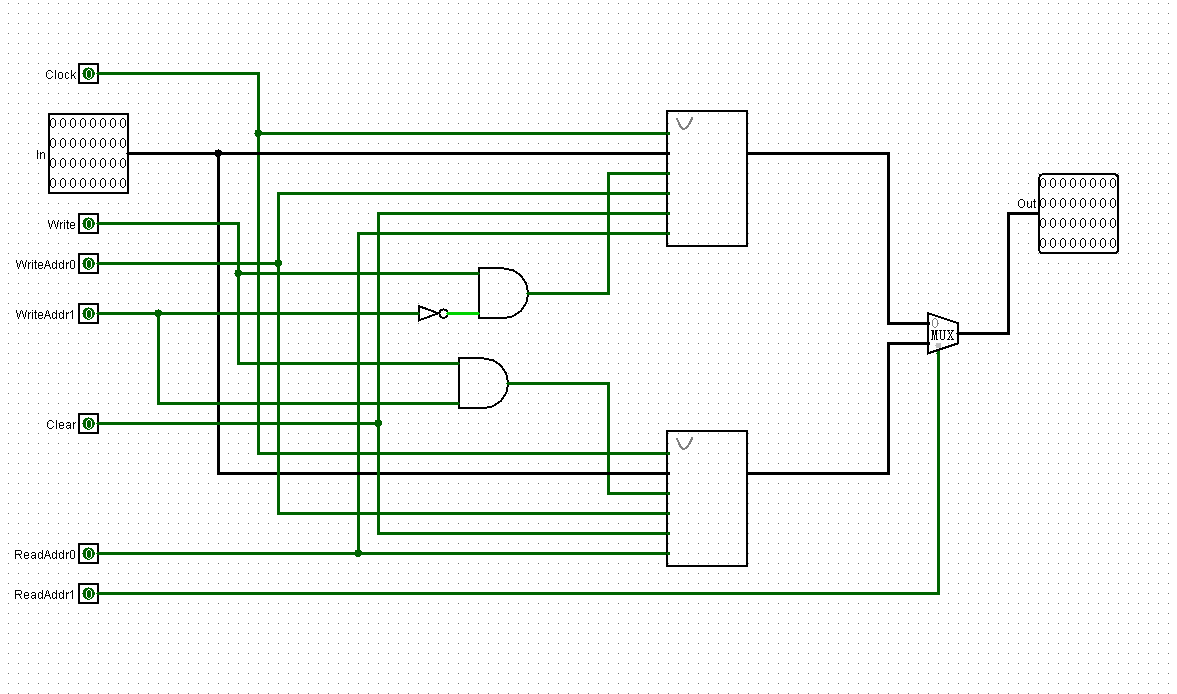
以此类推,组成GPR32:
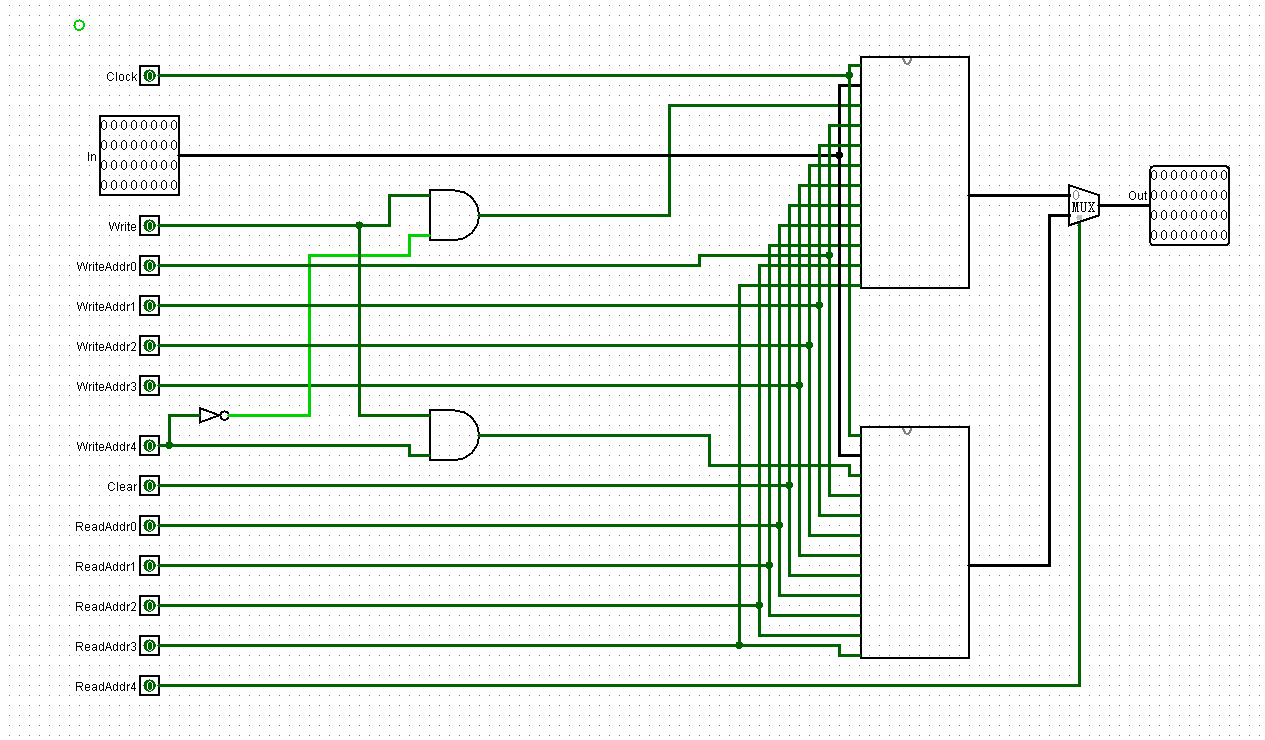
然后封装一下,大功告成:
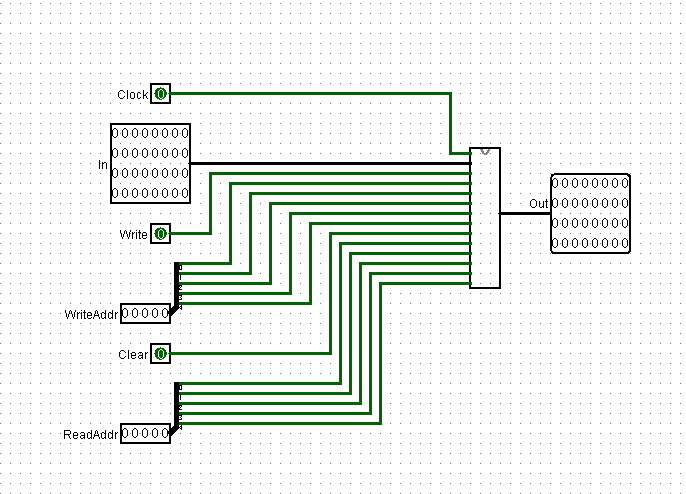
修改:两个读信号
由于是三总线结构,一开始设计的时候忘记了读信号有两个
不过好在修改容易:只需要把每个读信号单元复制一下就好
从GPR2开始改起
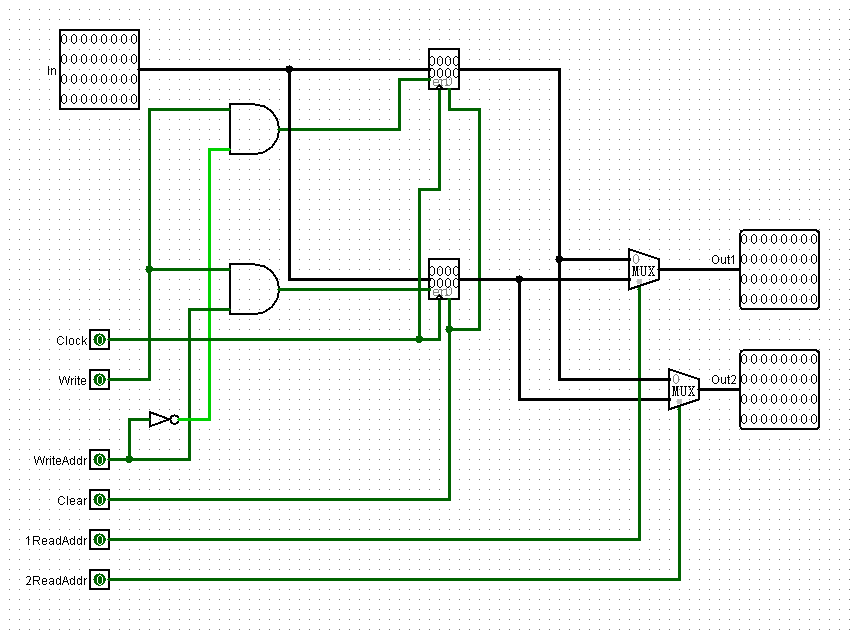
然后一层一层改,改了俩小时终于改完了:
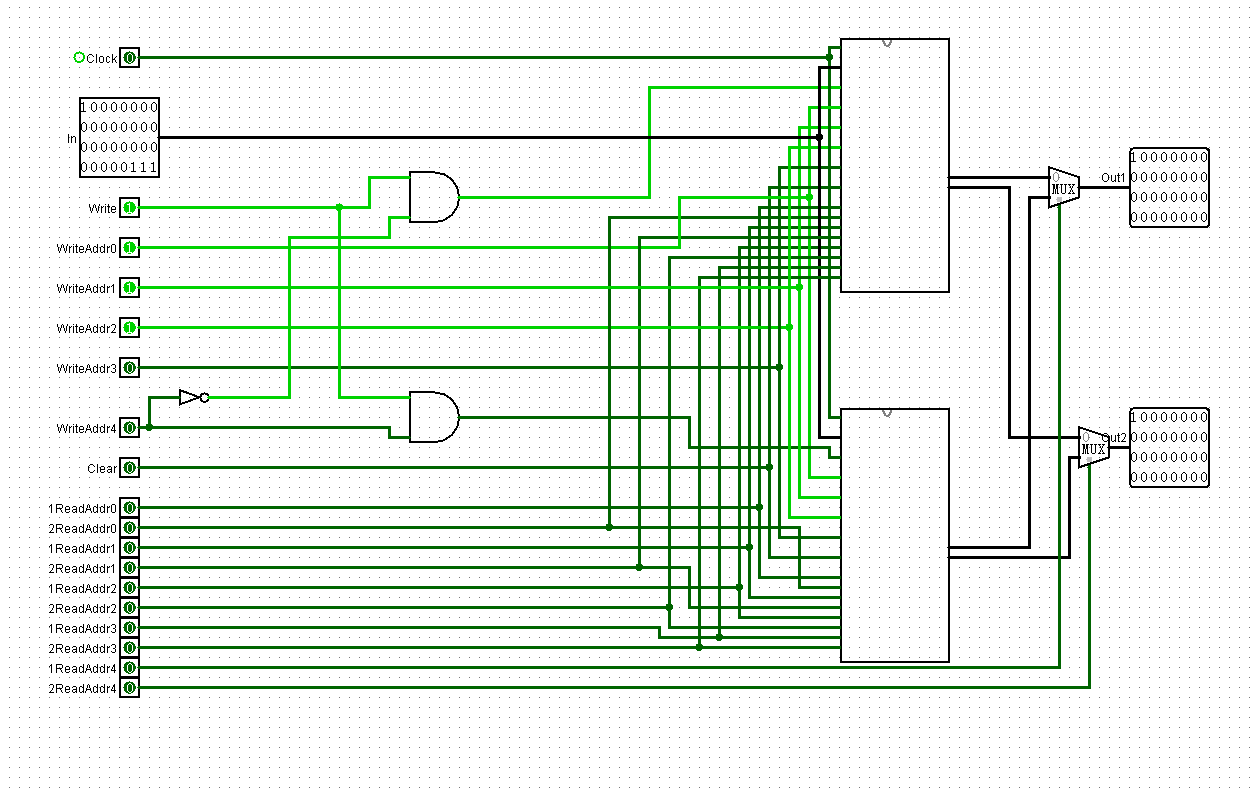
修改:Rd和Rt
还是要集成RegDst信号的,实现Rd和Rt选择功能
探针
进度推到上面的时候,突然被打断了,万恶的讲论文占用了我两周的时间——这两周基本上都在看论文,理解方法,做PPT,讲论文,挨批的大循环里,循环了三次,根本无心去做别的事情
时隔两周之后,终于有时间继续做了(为什么我想写作业还得拼命干活争取时间啊)
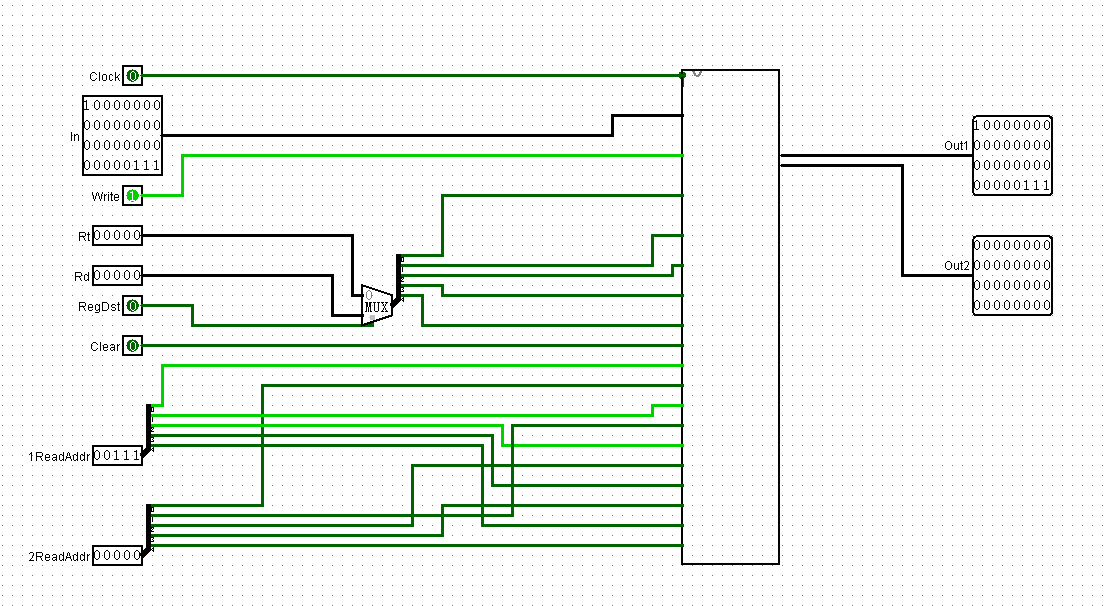
我决定从文档的头开始,首先是这样的图:
首先映入眼帘的是探针,我还特地查了一下,探针只不过是检测线路值的工具罢了
虚惊一场
那么现在缺的是什么呢?
好像只缺一个控制和连线了
Extender
还有一个extender,这里我有点不明白为什么extender需要一个控制信号,仔细一想或许懂了,可能ALU的B输入端要连一大堆这种,用到谁,谁就有输出吧
又遇到难题了,立即数拓展是什么拓展来着?
于是我去查了一下,ori是0拓展,而lw,sw则是符号拓展
那么控制信号会不会是决定立即数怎么拓展的呢,我觉得很有可能
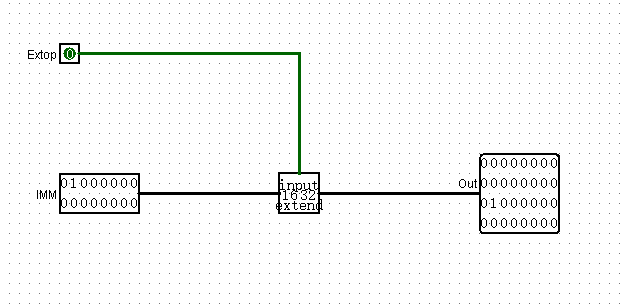
看了一下,果然是
更改一下外观:
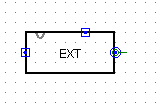
修改:符号拓展
Controler
之所以把它放在最后,当然是因为它最复杂
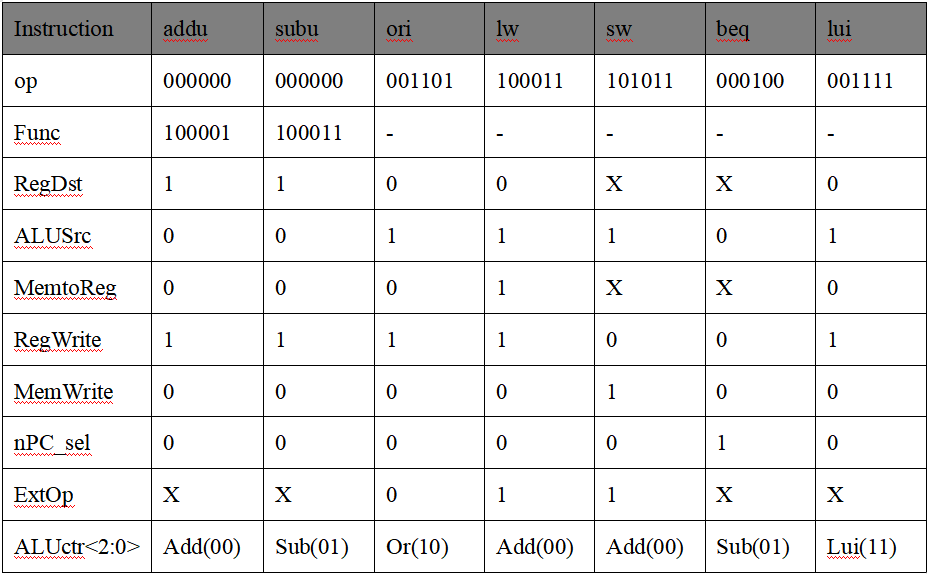
首先应该把每个指令和其对应控制信号列一张表,这里干脆把实验报告相应部分写了
查一下表https://ee.usc.edu/~redekopp/ee457/MIPS_Vol2.pdf,可以得到op和func的值
之后是Ext,需要扩展的只有ori,lw和sw,其中ori是无符号拓展为0,剩下两个是1,其它为X
然后是ALUctr,这里我注意到一个问题:示例里面是把加和减分开了,我没有,我使用了另外一个信号分的,我决定再去研究一下
好像确实不应该另加一个信号,我需要改一下ALU了
好,ALU已经改完了,现在00对应加,01对应减,10对应or,11对应lui
然后是RegDst,这个信号表示写入寄存器的时候,目标寄存器是Rd还是Rt
1表示Rd,0表示Rt,(这里我有点忘了,袁春风那本书自相矛盾,上面两张图是反的),原因是R型指令是Rs,Rt->Rd,I型则是Rs,IMM->Rt,目标不一样
写到这里,我意识到不对——我的寄存器堆写错了!
寄存器堆应该能支持同时读取两个寄存器的数据!
但仔细看了一下,好像也无妨,我只需要改一下,把寄存器堆的读口增加一个就好了,反正寄存器读数据是一直在读
改了俩小时寄存器堆,改完了,继续写控制表
addu和subu都是R型指令,存放到Rd里面,所以RegDst=1,而ori,lw,lui都是I型指令,RegDst=0,其它的指令用不到写寄存器,为X
ALUSrc是控制是否使用立即数那个多选器的,R型和beq都不用为0,I型都要用为1
现在已经可以初步连起组件
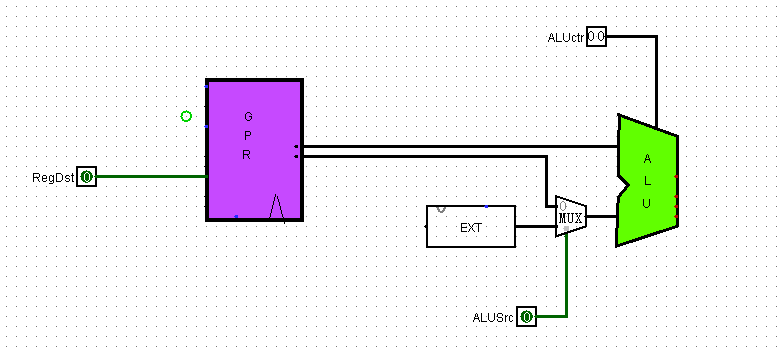
MemtoReg,往寄存器里写东西时,如果写入的数据是来自数据存储器,则MemtoReg为1,否则来自ALU,则为0
RegWrite,需要往寄存器里写东西则为1
MemWrite,需要往数据存储器写东西则为1
nPC_sel是分支指令,只有beq为1
真值表如下:
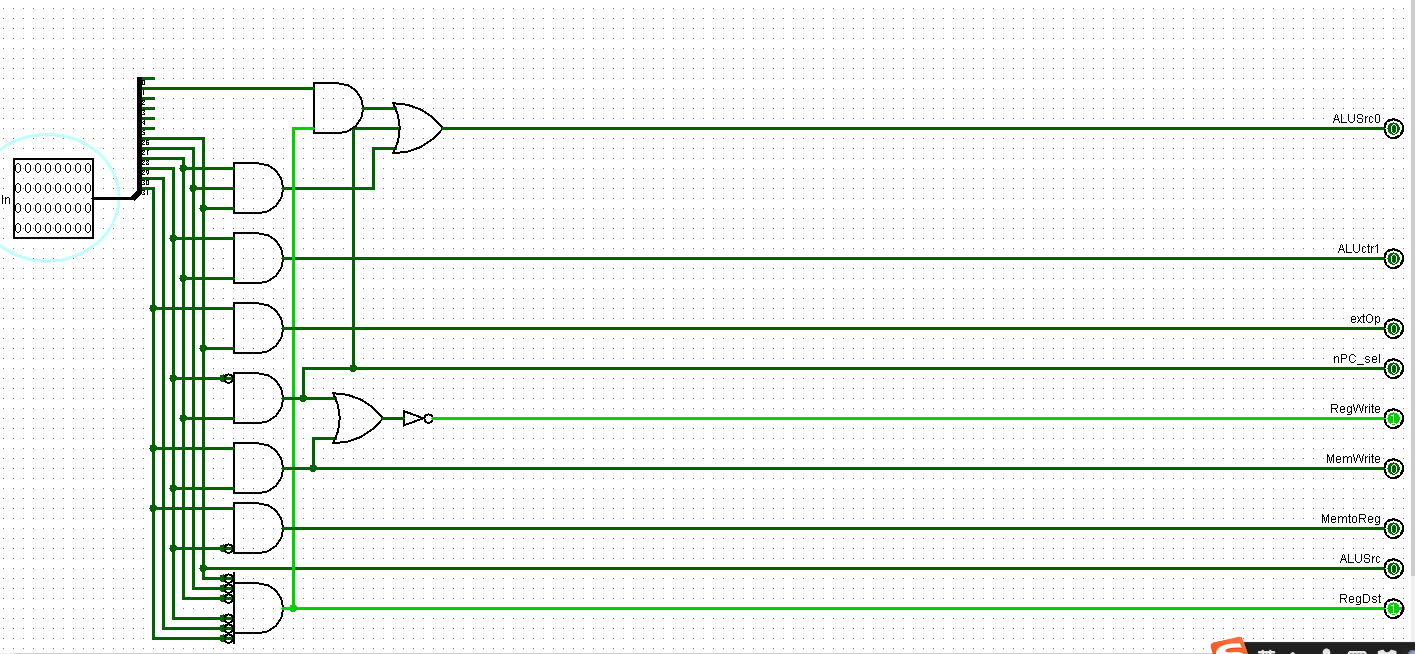
接下来就是根据真值表去设计译码电路了
最简单的是RegDst,凡是R型指令,RegDst=1,否则无脑0就行了
ALUSrc只与op的最后一位有关
MemtoReg第一位是1,第三位是0,此时可判断为1,否则都是0
RegWrite只有sw和beq是0,有些复杂,sw可以用MemWrite的反,beq的特点是第四位是1,第三位是0
MemWrite单独判断sw,只需要第一第三位是1则为1
nPC_sel单独判断beq
extOp这里其实只需要sw和lw是1即可,然后又想到一个问题,即使是sw和lw,也只是符号拓展,但我的ext好像此时是1拓展
赶紧去改
第一位和最后一位都是1,则extOp=1
ALUctr是最有意思的,首先看ALUctr的第一位,只有op第三第四位同时为1才会是1
ALUctr的第二位是比较复杂的,分两种情况
如果是R型指令,则与func的倒数第二位一样
若不是,则beq和lui指令时为1,可以把nPC_sel单独接过来
lui最后三位全是1,也接过来
这里想了想,还是把ALUctr弄成二位的
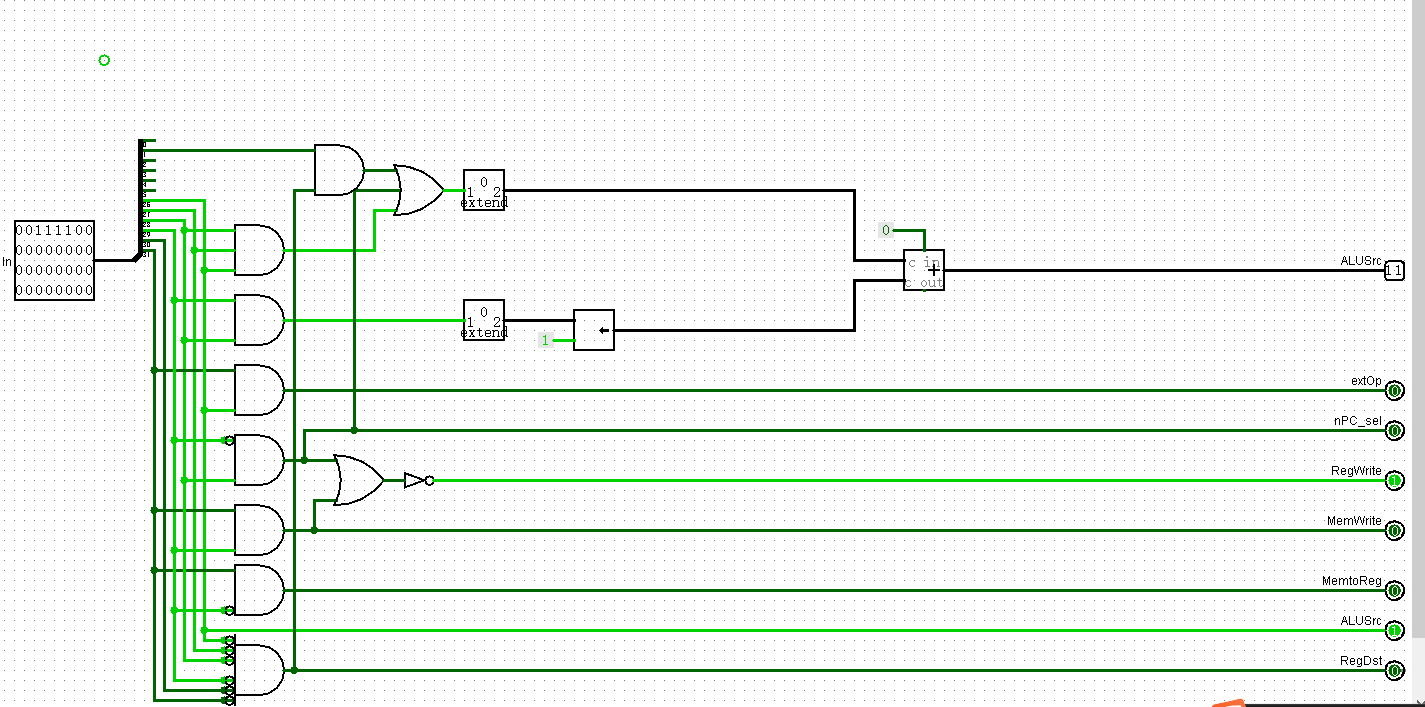
上面的ALUSrc就是ALUctr,这里忘改了
组装
把对应的信号都组装好,得到下图:
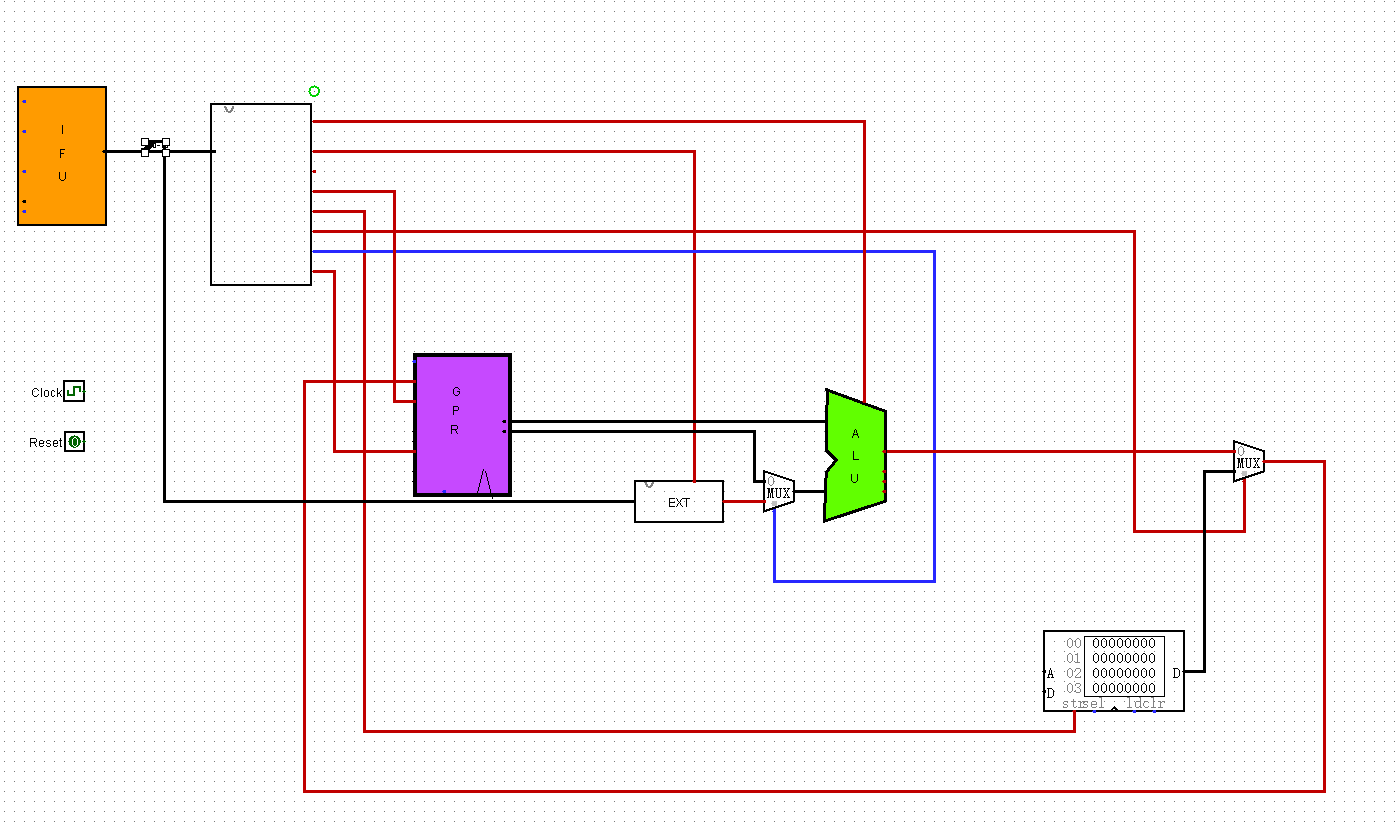
蓝色和红色应该是还没练好导致的吧,现在还差一个东西,就是译码Rd,Rs和Rt的东西,译码后连到GPR的相应位置,之后Mem操作那些我也没管
下午回来再弄吧
分离三个寄存器地址

这是一条R型指令,rs和rt应该分别对应了寄存器的两个读地址1readaddr和2readaddr
用分线器去分,连到对应端口就好
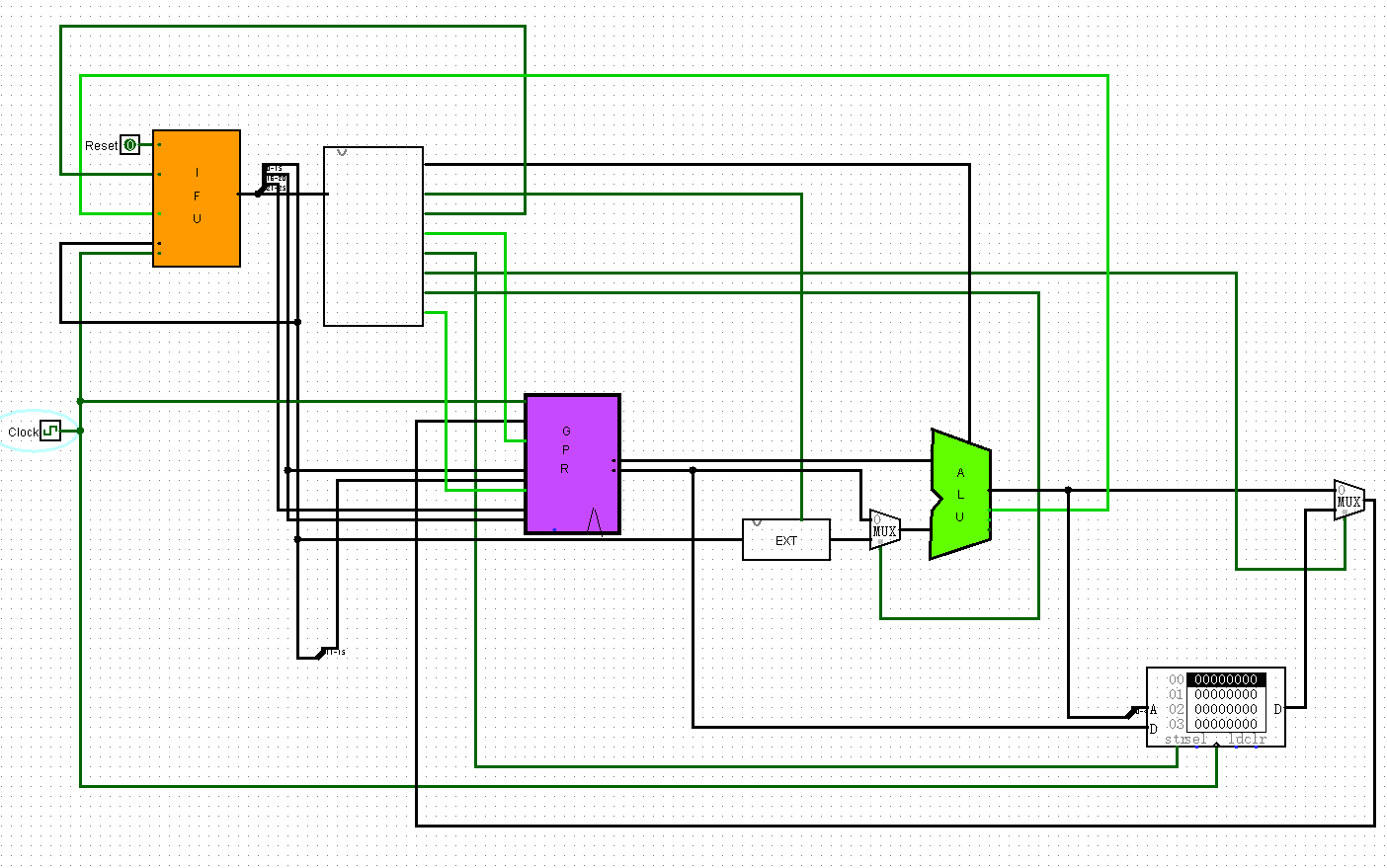
测试
去找这个该死的Mars,看看到底是个什么东西
http://courses.missouristate.edu/kenvollmar/mars/
download一波
不会用哎……
然后突然发现IFU错了,改一下
发微信问了那个老师,老师说其实就是为了生成机器码用的,和自己手搓也没啥区别
那我就明白了,我试着先照他实验报告去设置一下Memory Configuration
真让我找到了,就在Setting里
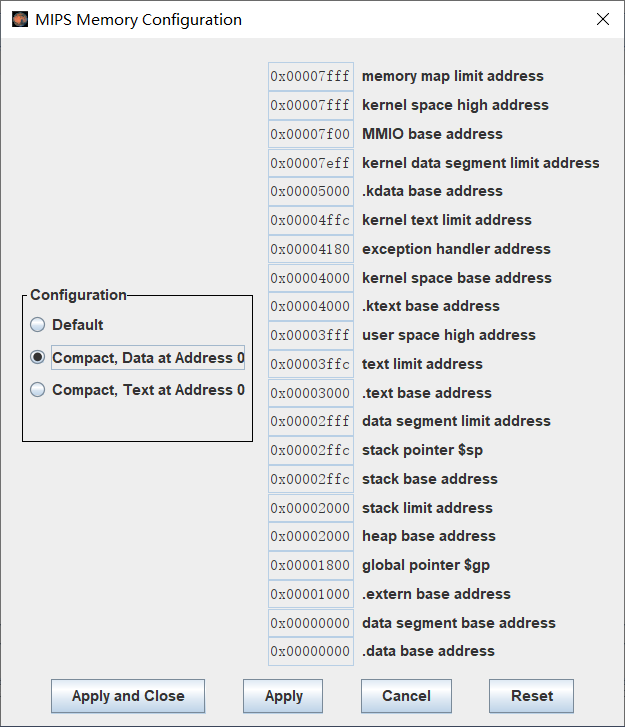
然后发现搞了半天,根本就没有需要设置的东西
这样的话,就搞几个测试样例吧
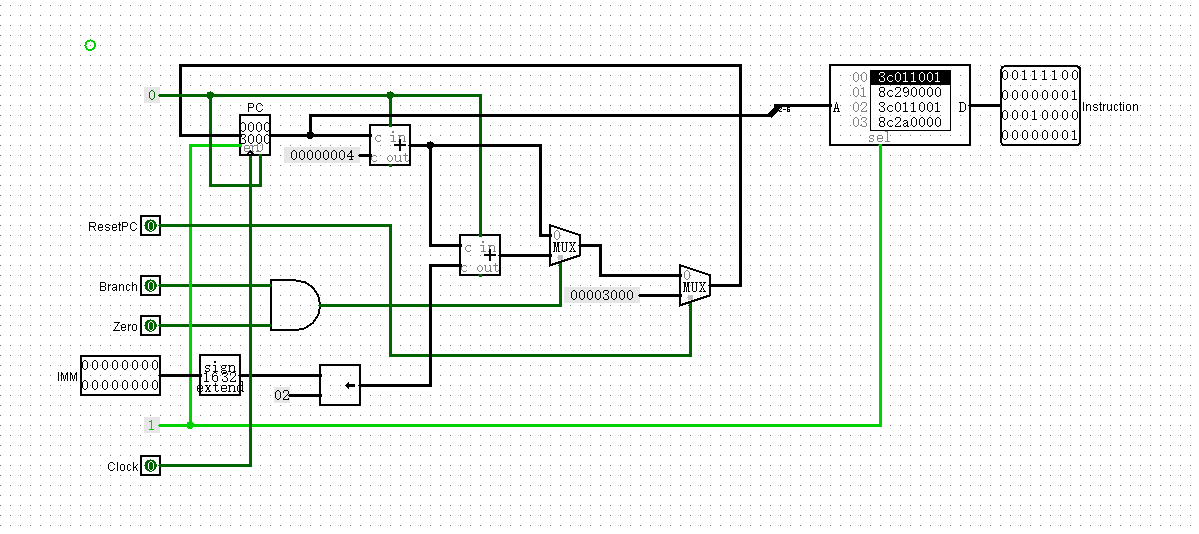
Test1
1 | .data |
编译后的机器码
1 | 3c011001 |
把这些机器码复制到IFU里面
数据段:把地址为0处的地方认为是a,赋值5
检查对不对的方式:先reset一下IFU,然后按clock执行,看最后地址为0的地方是不是变成了10(16进制a)
Test2
1 | .data |
内存00为5,01为10,最后检查00应该变成31,01变成5
这里测出来一个问题:数据段地址是00之后04(8bit),而我的内存是32bit的,所以要改一下
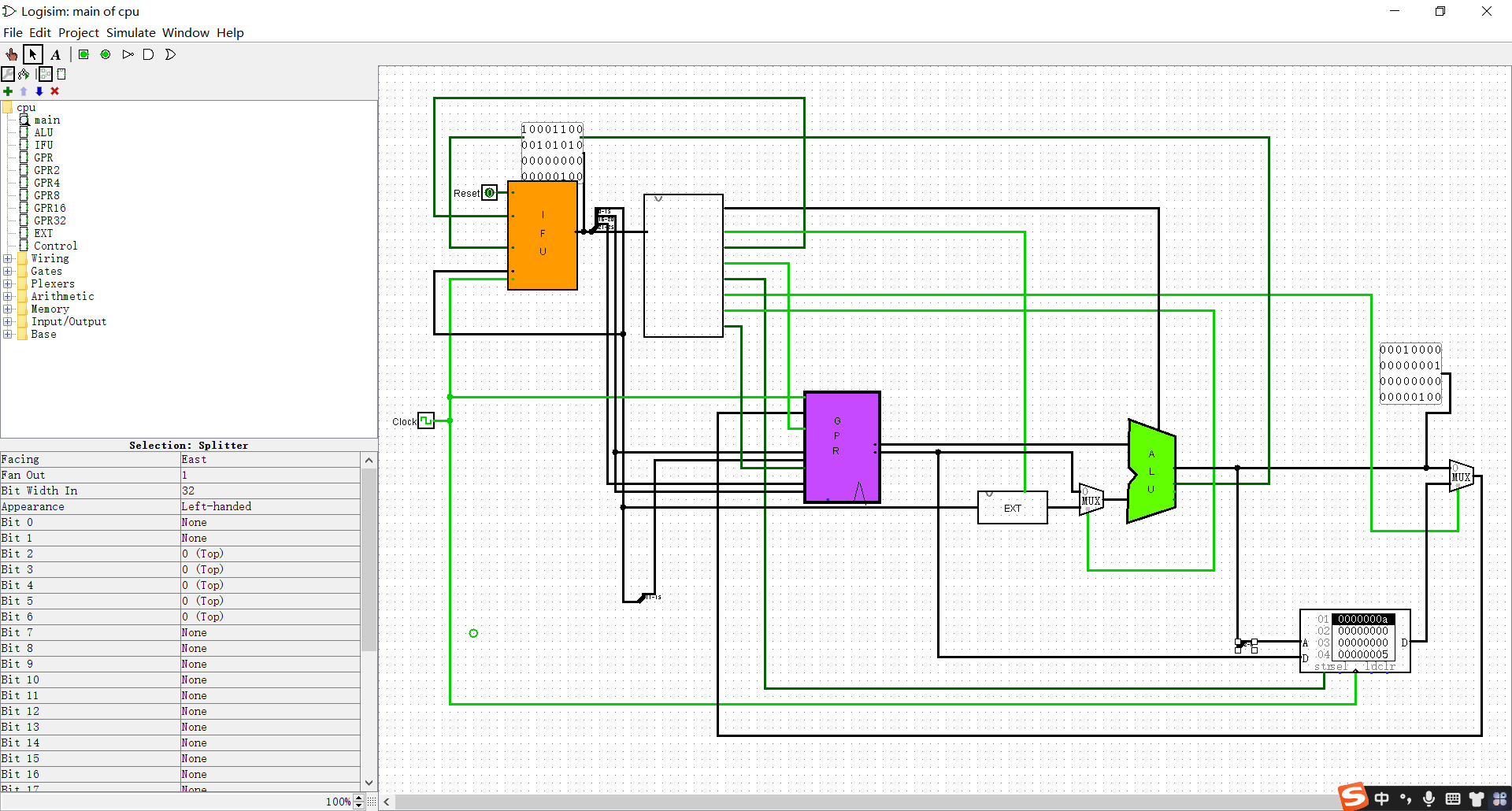
只改了进内存的那个分线器
然后样例过了
Test3
上述样例已经测试了addu,ori,lui(sw和lw会自带lui,具体可以看看Test1的机器码为什么多了两条,多的就是lui),sw和lw,还差beq和subu
1 | .data |
这个程序会让t2和t1相减得到t3,此时t1=t3=5
然后把t3的值更新b,并重新加载到t2里,得到t2=5
beq时会发现t1和t3相等,进入L1,此时再减会得到t3=0
更新后,t2=b=0
最后结果是a=5,b=0
也成功了,可以写报告了
Test4
报告说要设计20行以上的汇编程序来验证
所以缝合了一下:
1 | .data |