TFT时序框架
内容来自Lim, B., Arık, S. Ö., Loeff, N., & Pfister, T. (2021). Temporal fusion transformers for interpretable multi-horizon time series forecasting. International Journal of Forecasting.
过往研究的不足之处
预测方法
多步时序预测可以用下图表示
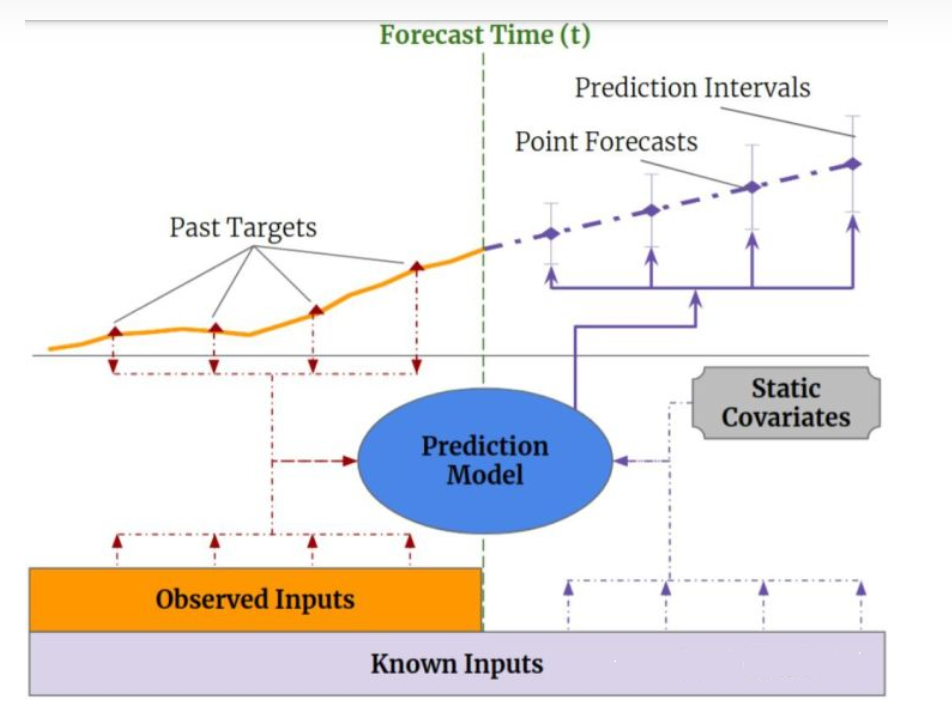
以风速预测为例,输入分为四部分
Past Targets就是过去的风速真实值
Observed Inputs是过去的观察值,比如温度之类,这一类数据无法提前知晓
Known Inputs是类似月份,季节这种虽然也随着时间变化,但是我们可以提前知晓的
Static Covariates是静态不变的,如风电场的海拔,位置
再以某商店内商品的销量预测为例,在时序预测中,所有的变量都大体划分为两大类:静态和动态,即随着时间改变和不随时间改变
静态变量再细分又可以分为离散和连续,离散的静态变量如商店的位置,所处的城市,商品的大类等
连续的静态变量如去年商品A在双十一的销量等等
动态变量也分为动态时变和动态时不变变量两种,这两种的区别是动态时变变量我们无法提前知晓,而动态时不变变量我们可以很容易推出来
举个例子就明白了——星期几就是一个典型的动态时不变变量,它虽然随时间变化,但是我们很容易推出来
讲完了输入变量和变量的分类,具体的预测方法如下图:
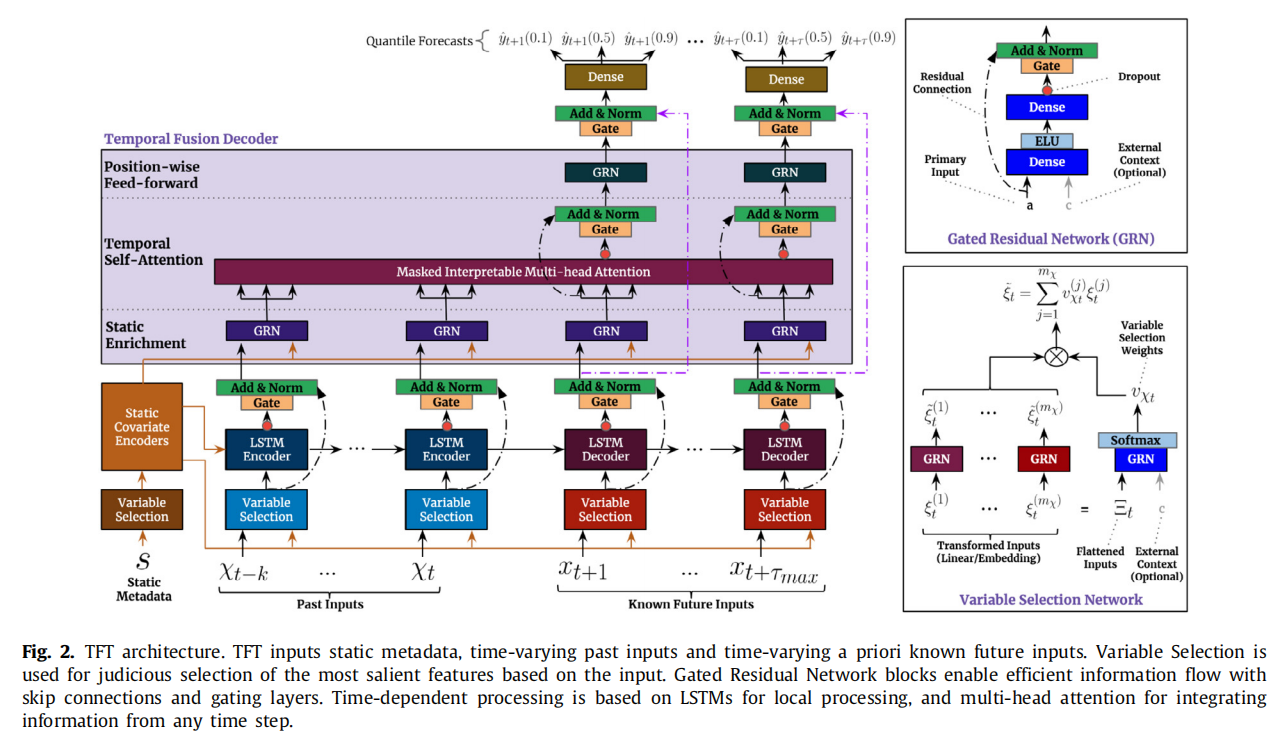
这个图,我先按照https://zhuanlan.zhihu.com/p/461795429是思路去拆解
输入层
大体上是一个双输入的结构,就是静态变量 + 动态特征
静态变量中的离散成分要接embedding再和连续成分concat,之后输入
embedding直译为嵌入,实际上是化离散为连续的过程——可以用一个embedding neural network来做,把离散的值映射到连续的空间中,并且一定程度上保留它们原本的特征
动态特征对离散值的处理也一样,区别在于t时刻(包括)之前的是所有的动态特征,t时刻之后的仅有动态时不变特征
VSN(Variable Selection Network)
之后就是一个varibale selection,顾名思义是变量提取,或者说,特征选择
GLU 门控线性单元
一般形式为输入X,输出:
1 | h(X) = (XW + b) * σ(XV + c) |
σ是sigmoid函数
如果在训练过程中,某个因素影响微弱,会使得值sigmoid之后趋于0,起到软性的特征选择作用
(原理未知)
GRN
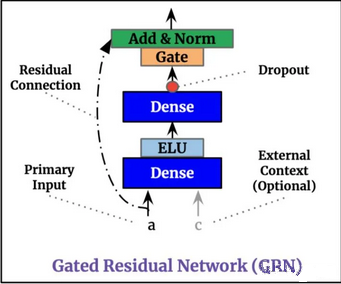
Gate对应的是上面的GLU,ELU是一个激活函数,其函数值如下:
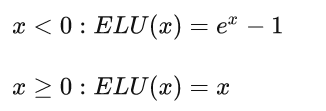
a和c先经过一个线性变换(第一个Dense),之后经过ELU,再经过一个线性变换+Dropdout后进GLU,得到的结果和初始的a相加,再进行normalization
之所以使用ELU作为激活函数,原因是:
ELU这个激活函数可以取到负值,相比于Relu这让单元激活均值可以更接近0,类似于Batch Normalization的效果但是只需要更低的计算复杂度。同时在输入取较小值时具有软饱和的特性,提升了对噪声的鲁棒性
(这些话我明白意思,但是,我不懂为什么)
a加上去是虚线,原因是为了让维度一致。同时a加上去本身是为了抑制非线性变化的速度。因为有些维度比较低比较简单的模型可能不太需要复杂的非线性变换,所以就相当于把a直接normalization了然后输出
选择
我不太明白这里的特征指的是什么,应该就是输入吧
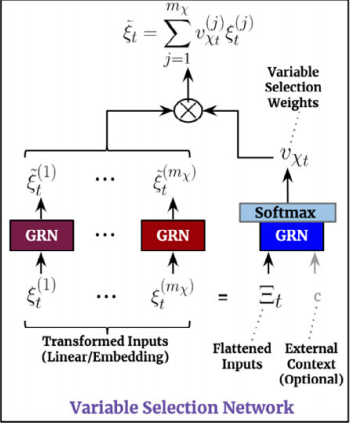
每个特征都过一下GRN,提取信息,之后再来一个从flattened inputs中得出的权重
我认为这样做的原因是为了让模型能够综合考虑所有特征的信息,而不是只依赖于单个特征的输出。通过拼接所有特征的输出向量,再应用一个GRN,可以让模型学习到一个高层次的特征表示,从而更好地判断每个特征对于输出的贡献。这也可以看作是一种注意力机制,让模型关注更重要的特征,忽略不相关的特征
所谓注意力机制,就是忽略不重要的,学习重要的,基于这种思想,给所有输入一个动态的权重
LSTM
他这里直接调的LSTM模板
Attention
首先讲一下什么是attention机制
attention就是要实现从关注全部到关注重点的一个转换
就像是我们看一张照片,可能不会发现照片的背景上有什么细节,但照片里的人我们会一眼就注意到
基于这个思想,attention机制最早出现在图像识别领域,真正将其发扬光大的则是在NLP领域
attention的三大优势,一是参数少,二是速度快,三是效果好,都是很好理解的——你把一张图片大部分都去掉了,只关注重点部分,可不是参数少了,速度快了。同时你的模型更加“专注”了,从而忽略掉了干扰项,效果也就好了
速度快还有一个原因——attention可以并行计算,这一点因为我对attention内部实现还了解不深,所以仅仅把它放在这
attention用于解决机器翻译问题,常常与Encoder Decoder框架结合使用
机器翻译的attention
单凭词语的替换是解决不了机器翻译问题的,比如早上好翻译成英文是Good morning,而不是morning good
为此,使用了一个Encoder-Decoder机制,将原始文本读入转换到隐藏层,从而获取文字的含义,再将隐藏层输出
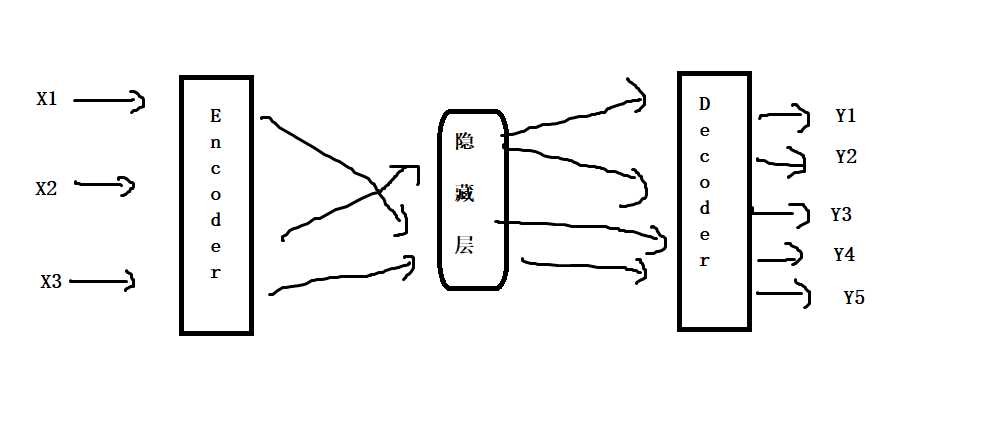
但这样做又会存在一个问题:当我们翻译大段大段的文字时,往往会出现隐藏层所能存储的信息不够了,通俗来说,就是模型有点“记不住”了
怎么会记不住了呢?一般隐藏层就是一个长度恒定的向量,既然是恒定的,它所能存储的信息就是有限的。我让它翻译一句话可以,我让它翻译一本书,可不就是记不住了吗
那我把一本书看成一句话,一句一句地翻译不就行了?
我猜测很多模型就是这样做的(因为用的很多翻译软件就是这样,丝毫没有上下文信息)
这不够好,尤其是复杂的文字——可能每句话之间有很强的逻辑联系或者有上下文关系。或者这个词是多义词,在当前语境下的翻译要考虑上下文等
这就需要attention出马了。在现实中我们也是这么做的——如果有人跟我们说话,我们往往只能根据几个关键词就能理解他的意思。如果我们去读书,可能根据几个关键词就能看懂某个章节
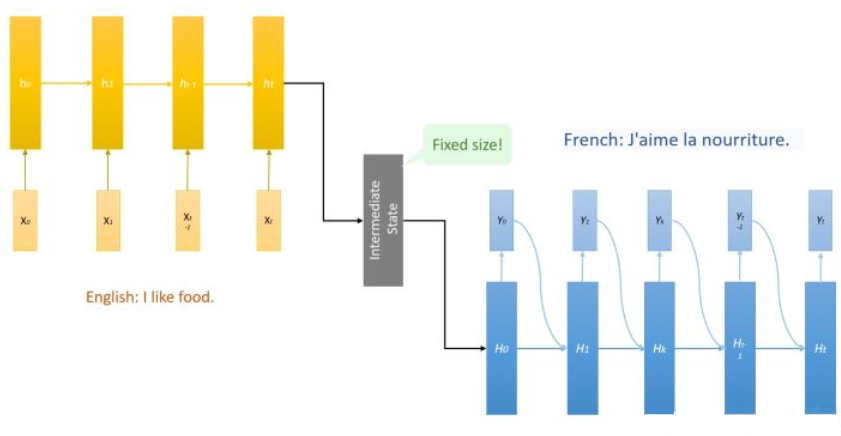
上图给出了一种翻译框架,Encoder中的隐藏层是ht,Decoder中的是Ht
可以看到的是,每个Ht以前一时刻隐藏层Ht-1和输出值yt-1为输入
写成式子就是Ht = f(Ht-1, yt-1)
这里,我们再引入一个C值,并且在每个时刻C值不一样,即在t时刻,我们引入Ct
Ht = f(Ht-1, yt-1, Ct)
这个Ct就是上下文向量,把它定义为原文隐藏层ht的加权平均
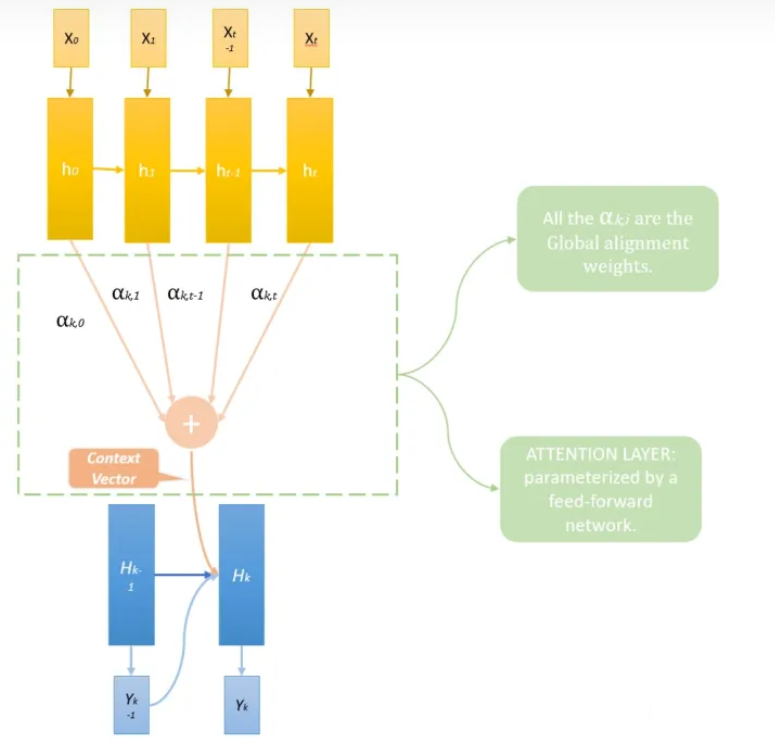
注意:每个Decoder隐藏层Hk都有一套完全不同的权重αk,这个权重就体现了应该对原文的注意力分配
又叫全局对齐权重
为了说明注意力的演变,举一个将法语句子“L’accord sur l’Espace économique européen a été signé en août 1992.” 翻译成英语句子“The agreement on the European Economic Area was signed in August 1992.”时,每一个输出英文词汇的α构成的对齐矩阵:

于是乎,该如何计算权重αk呢?似乎很复杂,所以我们用一个小的神经网络把它计算出来
αk的目的是想要知道,面对Hk-1时,应该给hk分配多少权重
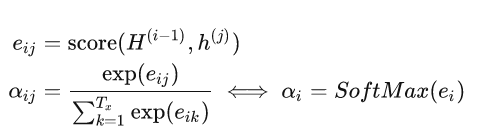
score有很多种,如:
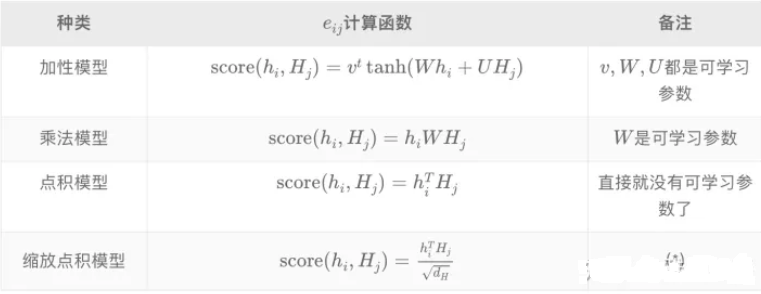
从Hhc到QKV
上述加性模型和乘法模型我们都好理解,无非就是通过优化参数,得到最好的注意力权重
那么点积模型是什么?连个参数都没有,我们该如何理解呢?
我们再回到最初的Encoder和Decoder,H是做什么用的?H是解码器的隐藏层,相当于根据之前的输出 + 编码器的隐藏层,得到当前的输出
再想想的话,就是说h相当于我要翻译的这句话的全部信息,H只不过起到一个查询的作用,对于不同的Ht-1,我根据h给出Ht,仅此而已
此时H就承担了权重的工作,此时我相当于取消了解码器的隐藏层——原本是用来存放待解码的信息用的
问题是,我需要存放这个信息吗?我有了编码器的隐藏层,我已经知道全部的信息了
所以H就变了,由一个存放信息的层变成了单纯表示权重的层
那再进一步想,我把h看做是包含了全部信息的图书馆,把H当成是一种查询或者寻址,以便于我找到应该输出的答案。那么原先的H就是查询Q,h就是键值K,输出就是答案Value
之前的NLP模型中,Q和V是相同的,都带着要输出的信息,无非一个是隐藏层,一个已经被解码了而已,但self-attention里Q和V是不同的
self-attention
K和V不同的话,我们相当于按照K去分配权重,然后利用这个权重来把V加权平均
score的值我们要同时根据k和q来计算(完全可以直接点乘)
假如我们的问题不再是翻译,而是想知道在一段话中处理某个词时,应该对其它的词分配多大的权重

假设这段文本中的每个词Wi经过词嵌入变成了Xi∈R,用三个矩阵Wk,Wv,Wq分别乘Xi得到三个表征
之后取出查询Q,对每个Ki计算全局对齐权重,最后把v按照该权重求和得到attention值
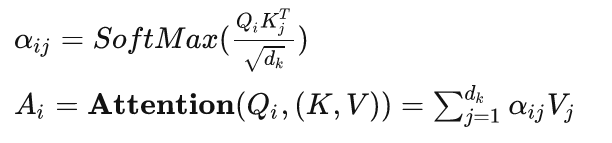
这里的dk是K向量的大小,将其缩小一定倍数的原因是防止SoftMax函数梯度过小
Transformer
说完了attention,就要谈谈transformer,Transformer类似一个CNN,可以在同一时间计算所有输入单词,并得到这些单词各自的表征向量。重要的是,这一次性的处理中得到的每一个表征向量都是在考虑到整句话语境信息以后的结果!这使得Transformer不再需要像RNN一样按照序列顺序处理信息,一来解决了长期依赖问题,而来也使得训练速度加快
而它正是基于self-attention机制的
![]()
其实相当于把一种数据翻译成另一种数据——我觉得应该可以用来做时序预测的特征提取
内部结构如下:
![]()
一般情况下包含六个编码器和六个解码器(我糙啊,为啥要六个,一个不够吗)
![]()
所谓feed forward(前馈网络),就是最简单的一个线性层 + 一个激活函数

说实话,怎么加入的attention我不懂
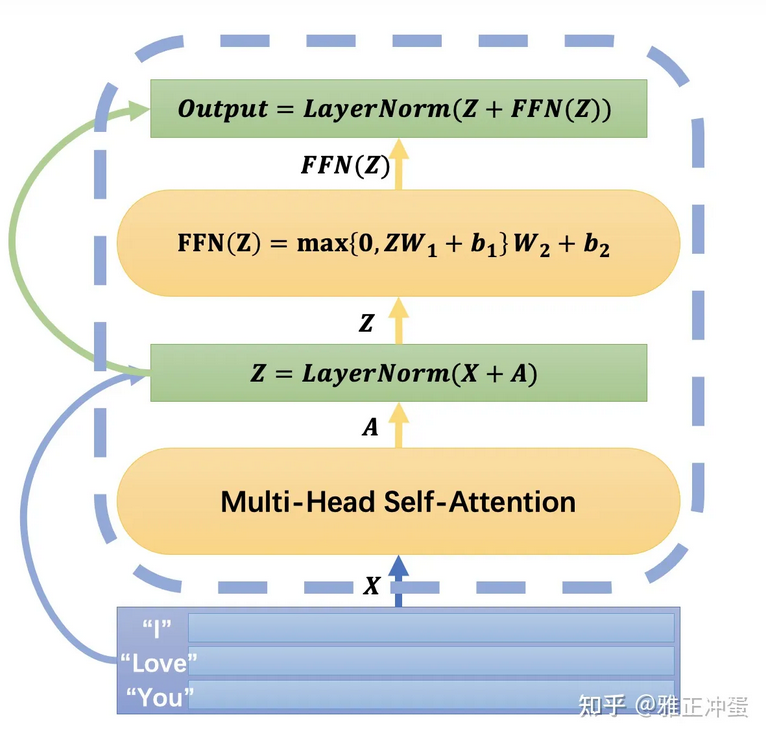
multi-head attention
多头attention,看完之后和我预想的不一样
我以为是对于多个查询分别训练出特定的”头”,实际上仅仅是增加了很多个Wq,Wv和Wk,每个x都乘这些Wq,Wv和Wk,因为有多组,所以会得到多组不同的q,v和k,然后最终结果也不一样,拼接起来线性转换成一个最终结果
我不明白这样的多头有什么好处呢,网上说多头的好处是能够关注的更加全面,捕捉不同的注意力
标准化

其实我感觉不是特别重要
Dense
multi-head attention之后再来个全连接层,其实就是一个前馈网络(FFN)
除此之外呢,还加入了残差连接
Decoder
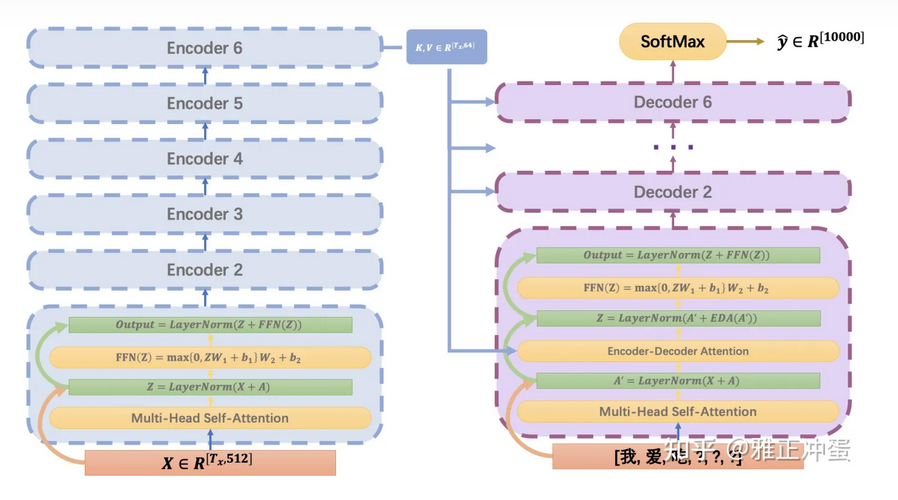
Decoder的结构如上图
除了和encoder一样的部分外,又加入了Encoder-Decoder Attention层
这是干什么的呢?
Encoder 6会输出A,我们把它乘个矩阵得到K和V,这个矩阵在每一次进入不同的Decoder时都是不一样的
然后呢,Q是上一次Decoder的输出
(这样好像没啥可解释性)
回到文章中
该文章只是使用了一个多头注意力机制,其中的V矩阵是所有头共享的(Wv)
分位数回归
其实就是换了个损失函数
TFT框架的代码
看这是个库,还以为实现起来不会很难,没想到到处都是坑,干脆还是看教程好了
如果教程里面也有坑的话,我也只能无能狂怒,问候他亲娘了
导入包
1 | import os |
导入了两个包,这里的warning.filterwarnings我是明白的,因为后面老是报让我ignore的warning,无视掉免得心烦
os.chdir我就不明白了,注释掉
1 | import copy |
依然是导入了一堆库,在后面应该用得上
读入数据
1 | from pytorch_forecasting.data.examples import get_stallion_data |
进入loaddata,这个data在pytorch的dataexample里,就很棒,减少了很多下载和格式之类的麻烦
我收回上面的话,因为我运行了一下发现它只是在内部下载而已,但我的代码被great wall挡住了,md
所以我又额外花了半小时的时间去下载数据集
下面是tutorial的翻译
1 | 首先,我们需要将时间序列转换为pandas数据框架,其中每一行都可以用一个时间步长和一个时间序列来标识。幸运的是,大多数数据集已经是这种格式了 |
我需要在下载下来的几个文件夹中,找到所谓的饮料销售数据集
然后我发现,这些都是饮料数据集,只不过每个表是一部分,比如我找到了一个calendar文件,明显在说每个月份里有什么节日
我现在的思路是去找读入这些数据集的代码
然后找到了Kaggle大赛的介绍,看了一眼,除了这个大赛里面有很多厉害的人,没什么有价值的信息
只能自己写了,我要给它一个pandas数据框
先看这个数据集里面有什么:
1 | price_sales_promotion.csv: |
看完之后,我们需要读入这些数据,先使用read_csv读入试试
1 | data = pd.read_csv(r'.\train_OwBvO8W\historical_volume.csv') |
结果:
1 | Agency SKU YearMonth Volume |
之后考虑怎么合并,再读一个price_sales_promotion.csv进来:
1 | data1 = pd.read_csv(r'.\train_OwBvO8W\historical_volume.csv') |
pandas.merge这里使用的是一个多行的外连接(并)
结果:
1 | Agency SKU YearMonth Volume Price Sales Promotions |
太好了,快都合并了吧
1 | data = pd.merge( |
人为给加上一个时间索引
1 | data['time_idx'] = data['YearMonth'] // 100 * 12 + data['YearMonth'] % 100 |
之后去掉不必要的YearMonth和Promotions
1 | data = data.drop(columns=['YearMonth', 'Promotions']) |
然后我就想摆烂了,我就拿着我现在的数据集往下走
创建dataset和dataloader
1 | 下一步是将数据框转换为PyTorch Forecasting TimeSeriesDataSet。除了告诉数据集哪些特征是分类的,哪些是连续的,哪些是静态的,哪些是随时间变化的,我们还必须决定如何规范化数据。在这里,我们分别对每个时间序列进行标准缩放,并表明值总是正的。通常,EncoderNormalizer会在训练过程中对每个编码器序列进行动态缩放,它可以避免由归一化引起的前视偏差。但是,如果您难以找到一个相当稳定的规范化,例如,因为您的数据中有很多零,那么您可能会接受前瞻性偏差。或者你期望在推理中有一个更稳定的规范化。在后一种情况下,您可以确保不会学习到在运行推理时不会出现的“奇怪”跳跃,从而在更真实的数据集上进行训练 |
接下来的代码,我们一点一点来看
1 | max_prediction_length = 6 |
什么是max_prediction_length?其实就是模型能向前预测的最大步数
那max_encoder_length是什么呢?是模型输入的历史数据点的数量
training_cutoff是最大的时间戳减去预测长度,很好理解
1 | training = TimeSeriesDataSet( |
上面的代码构建了一个timeseries,我们还是拆开来看
1 | data[lambda x: x.time_idx <= training_cutoff], |
lambda表达式是很有意思的东西,这里的x.time_idx < training_cutoff指的是所有time_idx在训练范围内的data
后面的含义都比较明显了,列出来主要是要明白时序预测需要指定什么
接着就是划分了,大体分为6类——static还是time_varying,然后categoricals还是reals。最后time_varying中又分为known和unknown
1 | static_categoricals=["Agency", "SKU"], |
后面这个time_varying_known_categoricals我不太明白,因为既然是special_days这种,是不是得搞个公式来计算啊
后来才回过味来,觉得自己想多了,只需要告诉模型就是了,模型又不是不会读后面的
至于为什么是reals,因为我没做节日的分类
1 | target_normalizer=GroupNormalizer( |
显然是在Agency和SKU组内进行数据的正则化
1 | add_relative_time_idx=True, |
这三项分别说,将时间跨度,输入尺度和编码长度纳入输入特征,是提高模型性能的,就直接用了
1 | # create validation set (predict=True) which means to predict the last max_prediction_length points in time |
生成验证集和dataloader,突然觉得这training_cutoff好短,分的有问题啊
不过先这么着吧
创建基准模型
1 | # calculate baseline mean absolute error, i.e. predict next value as the last available value from the history |
没问题,不愧是tutorial
TFT
终于到了重头戏
1 | # configure network and trainer |
pl.seed_everything(42)是将所有的随机种子设为42,这是为了让结果具有可重复性
gradient_clip_val=0.1则是对梯度进行一番控制,如果梯度的范数超过了0.1,将会把梯度调节到范数为0.1,这是为了防止梯度过大引起模型不收敛等问题
1 | tft = TemporalFusionTransformer.from_dataset( |
这里是定义了一个tft模型,打印了它内部的参数数量
1 | Global seed set to 42 |
之后为了找到最优的学习率
1 | # find optimal learning rate |
不懂就问,这不是已经在训练了吗

0.17782794100389226是最好的学习率
训练模型
我拿到学习率之后,把上面的代码删了
之后由于有个日志,我需要下载tensorboard和tensorboardX
1 | # configure network and trainer |
查看日志的命令
1 | tensorboard --logdir=lightning_logs/ |
风速预测并画图
仿照上面的写了代码
1 | import os |
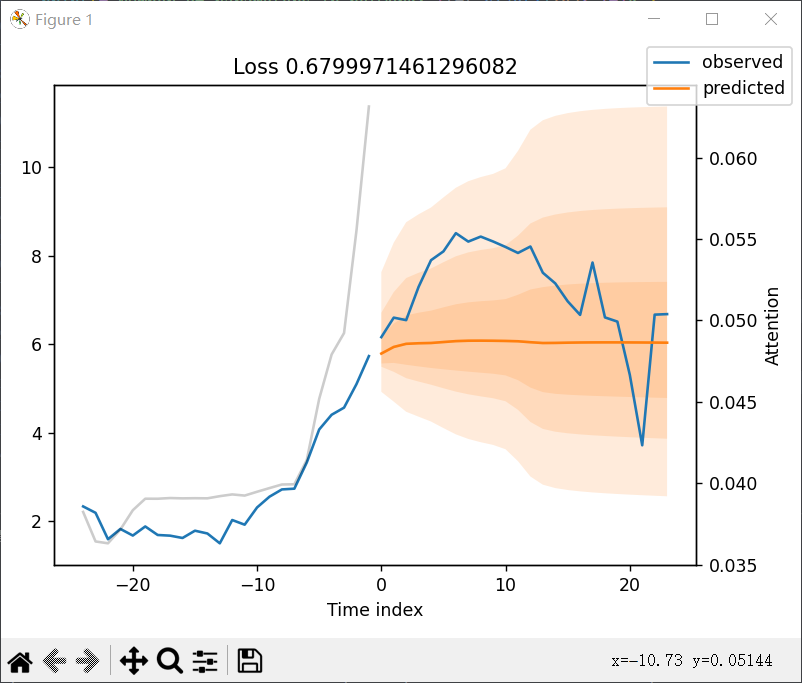
画出长时间的图
存储模型
虽然调好了,但是很遗憾的是,预测的结果看上去并没有那么理想,loss值也一直维持在0.6左右无法进一步下降
mape倒是挺低的,但是我却看不懂
然后我也不知道该怎么用这个模型做预测啊,我根本不知道他这个predict到底输入输出是个啥
输入我还算能理解,这个输出怎么会那么多
为了能够加快效率,免得每次调试一遍还得先训练,我得先学会怎么把模型存起来才行