开始之前,我们先简单说一下keras,keras其实是一个框架,一个库,机器学习一些常用的工具都在这里面有实现。其特点就是比较强调层,用它写起模型来,层次鲜明
https://keras.io/zh/layers/recurrent/
1 | import numpy as np |
上面是一段示例代码,还是一点点来分析
1 | import numpy as np |
首先说调用的库,np就是数组库,没什么好说的,Sequential是什么呢?
Sequential是个很重要的东西,类似于容器,一个模型一开始可以定义为一个空的Sequential,之后可以使用add方法往里面按顺序添加各层
之后,Dense是全连接层,Activation是激活函数层,Dropout是dropout层,后面用上了细说
LSTM就是我们要用的模型了
1 | x=[[1],[2],[3]]#特征 |
x和y的定义,这个特征我不是很理解,标签我也不是很明白,从一般习惯上来说,x是输入,y是输出,之后就是把x和y转为array,倒是没什么好说的
1 | x_train = np.reshape( x, (x.shape[0], x.shape[1], 1) )#Lstm调用库函数必须要进行维度转换 |
这句话啥意思?我可以确定的是x_train是在x的基础上加了一维,变成了3, 1, 1
为啥必须要维度转换啊,我不是很懂
1 | model = Sequential() |
先说说怎么建立模型,首先建立一个Sequential,然后调用add方法往里加层
至于顺序,就把Sequential理解为一个列表,先add进来的,进列表的底部
然后是LSTM了,LSTM接收了三个参数,一个是数字100,另一个是input_shape,还有一个是return_sequence
首先点开lstm类去看,它继承自RNN,我不是很懂python中的继承是怎么个用法,先去看了super的构造函数,return_sequence是直接传进去的
1 | def __init__( |
我糙啊,为什么lstm就没有input_shape,我就当这个100是units了
我去深挖一下,首先确认一下是不是调用了构造函数,答案是正确的,用类名+括号就是调用了构造函数
只有一种可能,input_shape在**kwargs里面
那么这个kwargs是个啥?原来,当我们指定一个函数的参数为不确定个时,哪些非指定的参数都会以字典的形式传到kwargs里面去
找!
1 | implementation = kwargs.pop("implementation", 1) |
上面就是对kwargs的处理了,看上去没什么关于input_shape的内容
1 | super().__init__( |
之后就把这个kwargs传到父类里了,就是这个super的kwargs
我们再把super点开,果然找到了input_shape
1 | if "input_shape" not in kwargs and ( |
赢!还想绕晕我,不可能的
那input_shape是个啥?网上搜是说输入张量的shape
我这里输入的是啥东西呢,x_train,shape是个啥?3,1,1
所以这里的shape调成了1,1
那他是啥意思啊,为啥非得是二维的不可?
这里就可以填上开头的一个坑了,为什么时序预测就得把x的shape给改了
一般的预测都是2D输入的,也就是说,第一维是不同的输入样本,第二维是每个输入的不同特征
时序预测是3D输入的,第二维的特征挪到第三维,第二维改成时间尺度
所以对于一个输入样本来说,模型会接收到一个二维的矩阵
相当于我这里给了三个输入,每个输入包含一个时间点,每个时间点包含一个特征
那units是什么?人说是隐藏层的大小
那什么是隐藏层呢?lstm里面的小框代表了一个经典网络的前馈连接层
units就是这些层里面隐藏层的数量
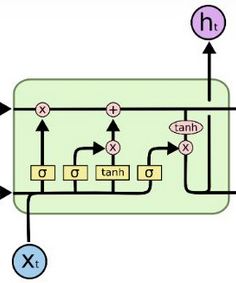
就是这上面图里小黄框内部的隐藏层
然后就是这个ruturn_sequences了,如果该值为true,则返回所有步的输出成为一个序列,否则只输出最后一个序列的值
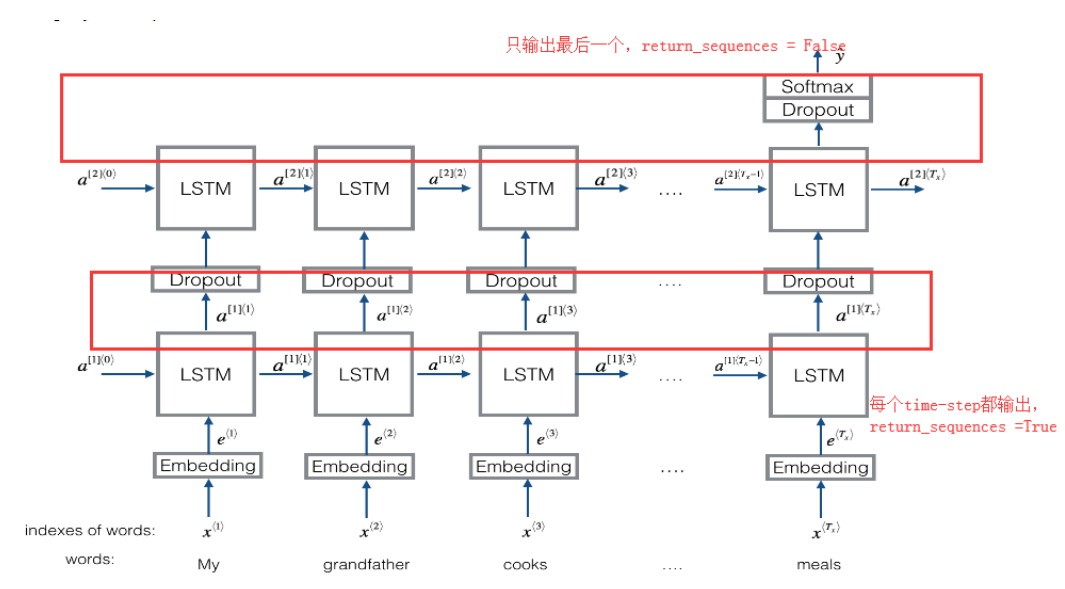
看上面的图可以清楚地理解,最后一层的lstm是要输出结果的,所以return_sequences是false,前面一层只是作为中间处理,还是要把中间结果传给下一层,所以是true
然后说一下Dropout层,首先,除了第一层之外,其它层的输入大小都是自动可以得出的,这里dropout在第二个lstm后面,我们可以知道它的输入和lstm的输出是一致的
1 | tf.keras.layers.Dropout(rate, noise_shape=None, seed=None, **kwargs) |
那它的输出是几维呢,我们打印网络的结构
1 | print(model.summary()) |
得到这样的输出
1 | Layer (type) Output Shape Param # |
我们可以看到dropout的output_shape是(None, 20),这个None代表的是批尺寸,None表示一次性把所有数据输入
把一个数据集都输入到模型里面训练一遍叫做一次epoch,一般会把数据集分成若干个batch,每个batch的数据量叫做batch_size
我们上面的代码没搞分批,如果是要把批大小为64的数据输进去,那么相当于一次有64个输入,这里的None就得改成64
这又反过来使我们理解了为什么一般的机器学习模型输入都是2D的:
一般机器学习的任务是一堆特征推出一个结果,是一维数组->一个点,然后为了训练,每次一批数据,就变成了一堆一维数组->一堆点
这一堆一维数组就是二维数组,其第一维是批大小,第二维是特征
时序呢,第一维仍然是批大小,但由于其输入是特征的序列,本身就是二维,所以变成了三维
仔细看一下lstm,第一个lstm输出了每个中间时段,但因为输入是(3, 1, 1),就一个中间时段,所以lstm第二维是1,第三维是隐藏层节点数100
第二个lstm因为只输出最终结果,所以相当于去掉了时段这一维度,只剩下了隐藏层20
dropout和激活函数层看样子都是不改变原来大小的
Dense声明的时候只给了一个参数1,那么说明只需要给一个输出维度就行
至此,上面的代码全都清楚了
1 | model.compile( loss="mse", optimizer="rmsprop" ) |
这里是为了确定模型的损失函数和优化器,其实还有一个参数叫metric,这是评估函数的意思——意味着有的时候,损失函数和评估函数不一致
上面的mes和rmsprop都是一些函数的代号,如果选择的话,库中还有其它一些函数
优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小
其实原理都是梯度下降为基础的,但有很多非凸函数,为了应对,搞了很多策略上去(比如加惯性之类的),导致优化器出现多种多样
1 | model.fit( x_train, y_train, epochs=200, batch_size=1) |
搞好了一切,现在就开始训练吧,参数分别是输入,输出,训练次数,批大小
我有点好奇,这里为什么没划分验证集呢,难道是自己划分的吗
查了一下,fit函数有validation_split参数,是用于划分的,这个参数在0和1之间
1 | test=[[1.5]] |
最后是搞了一个数据点来测试
之后就是把风速的数据用来测试了
想到这里我意识到,我的风速只有目标结果数据啊,根本没有输入,这该怎么办
我就想拿学弟的看一看,这个b怎么用的jupyter啊
就拿colab跑了一下
然后出了一个乌龙——我在数据预处理的时候做了一个填补工作,本意是把缺失的数据用前后数据的加权平均值来替代,没想到不小心把序号填进去了
然后loss一直100多万,降不下来
找了一天才揪出这个错,之后就好起来了
用96个点来预测96个点,MAPE为0.13
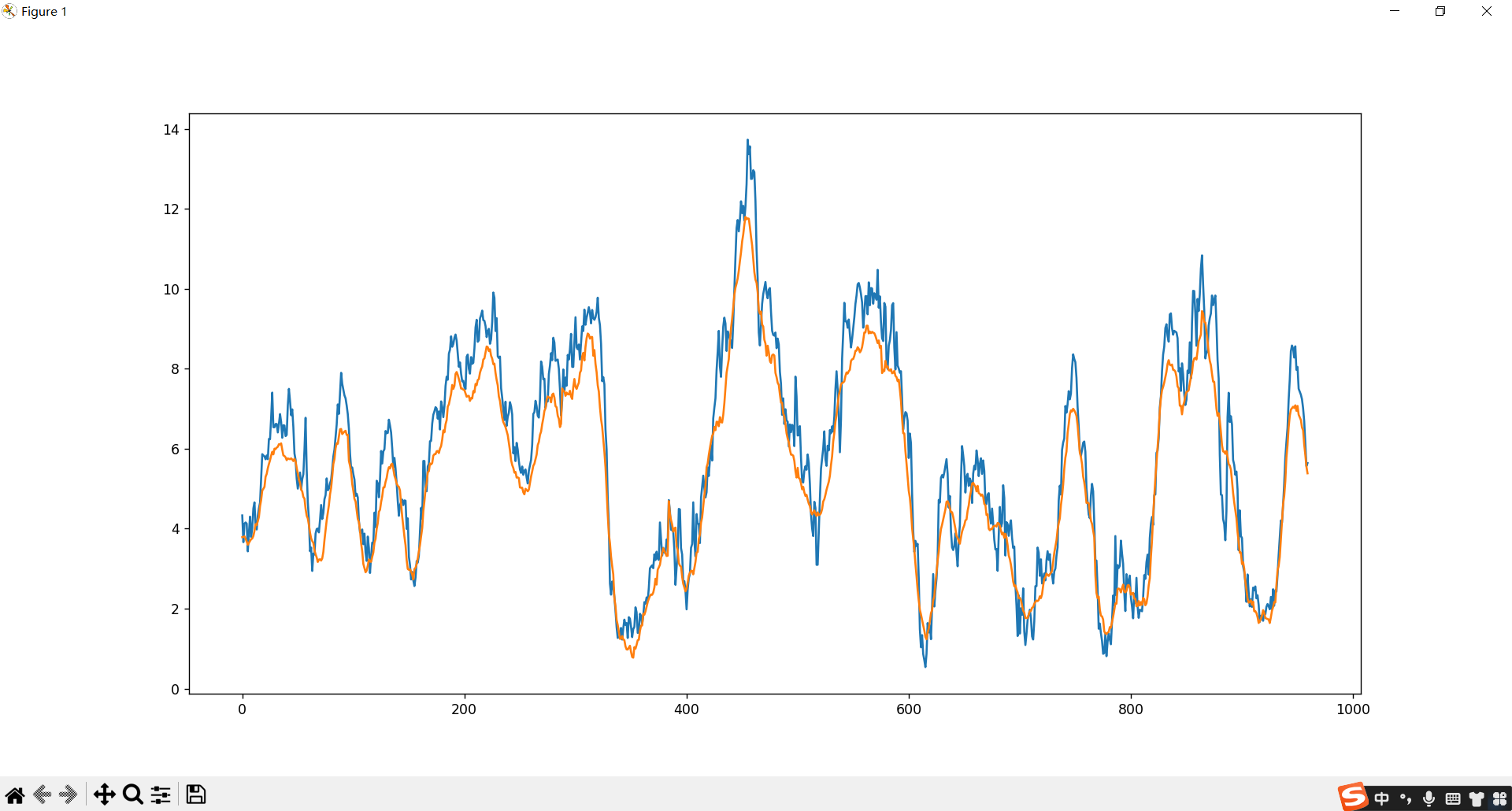
看上去还行,实际上好像结果也不咋样嘛
1 | import numpy as np |
之所以选择用96个点来预测96个点,是因为一般风速都是以一天为周期的
然后我又想到一个问题,既然一天为周期,我为啥不直接用昨天同一时间点的风速来预测今天的风速?
想到这里,我才明白了师弟模型的设计考量——他把一天的24个点看做是一天的特征,之所以不用值,而是用差分,也是为了从两天的差距中得到一个参考——理论上,同一时刻的两个点之间的差距应该是相关的
等我把激活函数换成swish之后,loss居然进一步降到了0.2(训练1000次以上)
下一步应该是增加其它特征了